현 문제점
현재 회사의 로그 관리는 따로 되지 않고 있다.
문제가 생기면 해당 서버의 로그폴더를 들어가, 문제가 된 일자.log에 들어가서...
위에서부터 하나씩 차례대로 읽어볼 수 밖에 없는 구조다.
그러다 보니 문제 확인하는데 한세월이 걸린다…
이걸 개선하고자 로그시스템 정확히는 plg stack에 대해 짧게 조사한 내용에 대해 적어본다.
log 시스템
로그시스템은 크게 3가지 흐름? 단계?로 요약이 가능하다. 수집/저장/조회 이렇게 3단계로 볼 수 있다.
시스템을 보기 앞서 자주 쓸 단어부터 정리하자면,
로그를 만들어내는 주체를 client, 로그를 저장하고 수집하는 주체를 server,
해당로그를 client로부터 server로 전송하는 agent라고 부른다.
방식으로는
client 에 agent가 존재해서 agent가 server로 로그를 밀어 넣는 방식 ⇒ agent-side push

server에 agent가 존재해서 agent가 client에서 로그를 당겨오는 방식 ⇒ server-side pull

다른 회사들의 로그 관리
해당 사안을 위해 검색해봤을때 주로
로그의 경우, 구조화된 데이터와는 다르게 비구조적인 텍스트 문자들이 주를 이루다 보니,
DB에 쌓기보다는(물론 DB에 넣는 곳도 많다) 주로 검색엔진에 넣고 조회할 때 사용하는 것 같다.
대표적으로 elasticsearch, logstash, kirbana (줄여서 elk) 스택을 사용하는 거 같았다.
아래는 코드너리라는 사이트에서 로그 수집 카테고리로 검색한 결과다. 물론 다른 방법들이 많이 있겠지만
elasticsearch도 꽤 많이 보이는 걸 확인했다.
문제는 elk+filebeat(agent)까지 회사에서 이미 도입해 봤고,
생각보다 많은 리소스를 잡아먹으면서 서버가 죽기 직전까지 갔다는 데 있다.
그래서 elk는 도입하기 어려울 것 같다고 말씀하셨고…
배달의 민족 업체인 우아한 형제 역시 해당 문제 때문에 로그시스템을 전환했다고 블로그에 적어놨더랬다.
따끈따끈한 전사 로그 시스템 전환기: ELK Stack에서 Loki로 전환한 이유 | 우아한형제들 기술블로그
안녕하세요. 클라우드모니터링플랫폼팀의 이연수입니다. 우아한형제들의 모니터링시스템 구축 및 관리, 운영을 하고 있습니다. 작년부터 올해 초까지 팀에서 전사 로그 시스템을 전환을 진행
techblog.woowahan.com
그 외의 tool들 아래와 같이 존재한다
- solution → datadog, graylog, sentry, newrelic (유료...ㅠㅜ)
- agent → filebeat, fluentd, vector (agent는 다 빠르고 좋은 듯...?)
- pipeline → logstash, kafka, vector (log를 빡세게 파싱해야 한다면 필요할 듯?)
- stack → elk, plg (stack으로 편하게 관리하려면..)
PLG
아래 stack에 보면 elk 말고 plg라는 게 보인다. 나도 이번에 검색해 보면서 처음 알게 된 건데
Promtail (agent), Loki (log engine), Grafana(dashboard)로 구성된 로그 시스템이다.

검색하면 참고자료가 많고, 이미 구성된 곳이 많은 elk 대신에 왜 plg를 쓰냐?
- 확장성 → elk와 plg 둘 다 필요시 확장이 가능하다. plg 정확히는 loki의 log 쓰기 모듈(write path), log 읽기 모듈(read path)을 나눠서 각자 확장이 가능!
- 비용 → 전체 텍스트를 인덱싱하는 elasticsearch에 비해, loki는 로그의 일부분만을 인덱싱 및 로그의 나머지는 압축해 저장해 놓는 방식을 통해 스토리지 및 메모리 공간을 절약하는 식으로 비용을 절감!
- 경험 → elk는 이미 회사에서 한번 적용했다가 안 맞는 부분을 발견했기 때문!
물론 회사마다 다르기 때문에 좀 더 찾아보고 비교해서 써봐야 할 것이다. 그치만 이번에는 plg로 구성해 볼 예정이다.
구성하기 전에 각 tool에 대해서 짚고 넘어가 보자.
promtail
promtail은 클라이언트 쪽에서 에이전트 역할을 하는데, 주요 기능들을 좀 정리해 보자면
- 로그 수집 및 전송: 설정한 경로에서 로그 파일을 읽어서 Loki로 보내준다.
- 라벨링: 로그에 메타데이터를 붙여서 나중에 쉽게 찾고 필터링할 수 있게 해 준다.
- 유연한 설정: YAML 파일로 로그 소스, 라벨, 스크래핑 간격 같은 걸 세세하게 조정할 수 있다.
- 위치 추적: 각 로그 파일을 어디까지 읽었는지 기억해 두고, 재시작해도 그다음부터 읽는다.
- 전처리 및 변환: 정규식으로 로그 라인을 파싱 하거나 라벨을 뽑아내는 것도 가능하다.
- 멀티테넌시: 여러 Loki 인스턴스로 동시에 로그를 보낼 수 있어서, 복잡한 로그 관리도 가능하다.
Promtail은 가볍게 설계돼서 리소스도 적게 쓰면서 처리량이랑 안정성은 높고
이런 특징 때문에 큰 규모의 분산 시스템에서 로그 수집하기 좋고, Loki랑 같이 쓰면 로그 관리를 효율적으로 할 수 있다고 한다
(쓰면서 느낀 건 설치 -> config파일 수정 -> 실행하면 알아서 쭉쭉 log 뽑아다 넣어준다... 우왕...)
grafana
Grafana는 데이터 시각화 및 모니터링을 위한 오픈소스 플랫폼
다양한 데이터 소스(Loki, Prometheus 등)와 연동하여 대시보드를 생성할 수 있으며,
실시간 데이터 분석과 알림 설정이 가능!
나도 맨날 말로 들어보기만 했지 이번에 처음 써봤는데 와... 그냥 이거만 있어도 되겠다 싶었다.
Loki
Grafana Loki는 로그 집계 시스템으로, Prometheus 및 Kubernetes와 같은 시스템에 최적화되어 있고
주요 특징은
- 효율적인 저장: 로그 내용 대신 메타데이터에 인덱스를 생성하여 저장 공간을 절약
- 쉬운 운영: 단일 프로세스 모드부터 마이크로서비스 아키텍처까지 다양한 배포 옵션을 제공
- LogQL: Prometheus의 PromQL과 유사한 쿼리 언어를 사용하여 로그 검색 및 집계가 가능
- 멀티 테넌시: 여러 팀이나 고객의 로그를 안전하게 분리하여 관리
- Grafana 통합: Grafana와 원활하게 연동되어 로그 데이터를 시각화 용이
Loki는 대규모 로그 데이터를 효율적으로 저장하고 검색할 수 있다고 하는데 실제로 구성해 봐야 알 거 같다...
loki의 아키텍처

Loki의 아키텍처는 크게 write path, read path, storage로 구성되어 있다.
- Write Path: 로그 데이터를 수집하고 저장하는 경로, 로그 에이전트(예: Promtail)로부터 데이터를 받아 Loki의 저장소에 기록
- Read Path: 저장된 로그 데이터를 검색하고 쿼리 하는 경로, 사용자나 Grafana와 같은 시각화 도구의 요청에 따라 로그 데이터를 검색 및 반환
- Storage: 로그 데이터와 인덱스를 실제로 저장하는 컴포넌트. Loki는 효율적인 저장을 위해 로그 내용 대신 메타데이터에 인덱스를 생성/ 저장 공간을 절약.
loki의 로그를 저장하는 방식

Loki의 로그 형식은 주로 다음과 같은 구조를 가진다
- 타임스탬프: 로그 생성 시간을 나노초 단위의 정밀도로 기록한다.
- 라벨 세트: 로그 엔트리를 분류하고 식별하는 키-값 쌍
- job: 로그를 생성한 작업 또는 서비스 이름
- instance: 로그를 생성한 특정 인스턴스 또는 호스트
- level: 로그의 심각도 수준 (예: info, warn, error)
- 기타 사용자 정의 라벨
- 로그 라인: 실제 로그 메시지 내용으로, 주로 비구조화된 텍스트 형식이다.
Loki는 이 구조를 활용해 로그를 효율적으로 저장하고 검색한다:
- 인덱싱: 라벨 세트에 인덱스를 생성해 빠른 검색을 지원한다.
- 압축 저장: 로그 라인을 압축해 저장 공간을 최적화한다.
- 시계열 데이터베이스: 타임스탬프를 기반으로 로그를 시계열 데이터로 관리한다.
이러한 접근 방식으로 Loki는 대량의 로그 데이터를 효율적으로 처리하면서 빠른 쿼리 성능을 제공한다.
loki의 write path

Loki의 Write Path는 로그 데이터가 Loki 시스템에 유입되어 저장되는 과정을 나타낸다.
이 과정은 주로 다음과 같은 컴포넌트들로 구성된다
- Distributor:
- 유효성 검사: 들어오는 로그 데이터의 형식과 내용 검증
- 전처리: 필요시 로그 데이터 정리 또는 포맷 조정
- 속도 제한: 과도한 로그 유입 방지를 위한 속도 제한
- Ingester:
- 청크 처리: 로그 데이터의 효율적인 크기의 청크로 묶음
- 데이터 복제: 고가용성을 위한 여러 Ingester 간 데이터 복제
- Timestamp Ordering: 로그 데이터의 시간 순서 정렬
- Storage:
- 로그 데이터와 인덱스의 영구 저장소 기록
- 일반적으로 객체 스토리지(예: S3, GCS) 또는 로컬 파일 시스템 사용
이 과정을 통해 Loki는 대량의 로그 데이터를 효율적으로 처리하고 저장할 수 있으며, 후속 검색과 분석을 위한 기반을 마련한다.
loki의 read path

Loki의 Read Path는 저장된 로그 데이터를 검색하고 쿼리 하는 과정을 나타낸다.
이 과정은 주로 다음과 같은 컴포넌트들로 구성된다:
- Query Frontend:
- 사용자 또는 Grafana와 같은 시각화 도구로부터의 쿼리 요청 수신
- 쿼리의 분할 및 병렬화를 통한 처리 효율성 향상
- 쿼리 결과 캐싱을 통한 반복적 쿼리의 응답 시간 개선
- 쿼리 요청의 큐 관리를 통한 과도한 부하 방지
- Querier:
- 실제 로그 데이터를 검색하고 필터링하는 역할을 수행
- 인메모리 캐시와 영구 저장소 모두에서 데이터를 검색
- LogQL을 사용하여 복잡한 쿼리 및 집계 작업을 수행
- 필요한 경우 여러 Ingester와 Storage에서 데이터를 병합
이 과정을 통해 Loki는 대량의 로그 데이터에서 빠르고 효율적인 검색 및 분석 기능을 제공한다. Query Frontend가 쿼리 최적화와 부하 관리를 담당하고, Querier가 실제 데이터 검색과 처리를 수행하는 구조로, 대규모 로그 데이터에 대한 빠른 응답 시간과 확장성을 보장한다.
loki의 storage
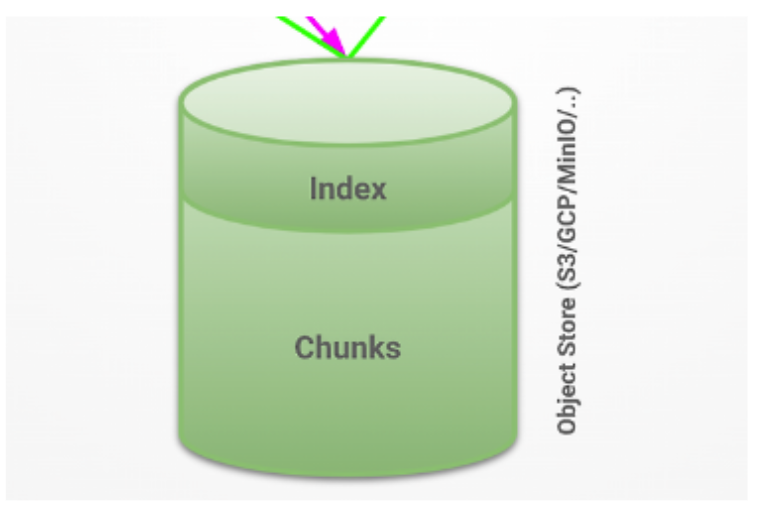
Loki의 스토리지 컴포넌트는 로그 데이터를 효율적으로 저장하고 관리하는 요소다.
이 시스템은 시계열 데이터베이스(TSDB) 원칙을 기반으로 설계되어 있으며, 다음과 같은 주요 특징을 가지고 있다
- 시계열 데이터 저장: Loki는 로그 데이터를 시간 기반으로 저장, 이 방식은 시간에 따른 로그 검색과 분석을 효율적으로 수행
- 클라우드 오브젝트 스토리지 지원: Amazon S3, Google Cloud Storage 등의 클라우드 오브젝트 스토리지 서비스와 통합 가능!
이를 통해 대규모 로그 데이터를 안정적으로 저장하고 관리 - 파일 시스템 지원: 로컬 또는 네트워크 파일 시스템을 사용하여 로그 데이터를 저장
(이는 소규모 환경이나 온-프레미스 솔루션에 적합하다고 production환경에선 웬만해서는 하지 말라고 document에 적혀있음;;;)
Loki의 스토리지 시스템은 인덱스와 청크라는 두 가지 주요 구성 요소로 나뉘는데
- 인덱스: 로그 스트림을 빠르게 식별하고 검색할 수 있도록 하는 메타데이터 저장소다. 이는 주로 라벨과 타임스탬프 정보를 포함한다.
- 청크: 실제 로그 데이터가 저장되는 곳이다. 청크는 압축되어 저장되며, 효율적인 저장과 빠른 검색을 가능하게 한다.
이러한 구조를 통해 Loki는 대량의 로그 데이터를 효율적으로 저장하고 빠르게 검색할 수 있는 능력을 제공한다. 또한, 클라우드 스토리지와의 통합은 확장성과 안정성을 보장하며, 다양한 환경에서의 유연한 배포가 가능하다고 한다.
loki의 agent
Loki는 다양한 방식으로 로그를 수집하고 전송할 수 있도록 지원한다.
- API 지원: Loki는 HTTP API를 제공하여 직접 로그를 전송 가능
- Third-party 에이전트 지원: Fluentd, Vector 등의 인기 있는 로그 수집 도구들과 통합 가능
- Java 로깅 프레임워크 지원:
- Log4 j2: Loki로 직접 로그를 전송할 수 있는 appender를 제공
- Logback: Loki와 통합된 appender를 사용하여 로그를 전송
이러한 다양한 지원 옵션을 통해 Loki는 기존 시스템과의 통합을 용이하게 하고,
사용자의 요구사항에 맞는 유연한 로그 수집 환경을 구축할 수 있도록 한다.
Loki의 배포(deployment) 종류
Loki는 세 가지 주요 배포 모드를 제공하는데 아래와 같다.
Monolithic 모드:
- 모든 컴포넌트(읽기, 쓰기, 백엔드)가 단일 프로세스에서 실행
- 소규모 환경에 적합하며, 일일 약 20GB 이하의 로그 볼륨을 처리
- 설정과 관리가 간단하지만 확장성에 제한

Simple Scalable 모드:
- 읽기, 쓰기, 백엔드 컴포넌트가 분리되어 독립적으로 실행
- 각 컴포넌트를 필요에 따라 개별적으로 확장
- 로드 밸런싱을 위한 프록시가 필요
- 일일 수 TB의 로그 처리가 가능한 중간 규모 환경에 적합

Microservices 모드:
- 모든 컴포넌트(Compactor, Distributor, Index Gateway, Ingester 등)가 완전히 분리되어 실행됩니다.
- 각 컴포넌트를 독립적으로 확장할 수 있어 최대의 유연성과 확장성을 제공합니다.
- 주로 Kubernetes 환경에서 운영되도록 설계되었습니다.
- 대규모 환경과 복잡한 요구사항을 가진 시스템에 적합하지만, 설정과 관리가 가장 복잡합니다.

로그데이터 저장소
Loki는 로그 데이터를 저장하기 위해 TSDB(Time Series Database) 방식을 사용한다.
TSDB는 시간에 따라 변화하는 데이터를 효율적으로 저장하고 검색할 수 있도록 설계된 데이터베이스 유형이다.
이 방식은 로그 데이터와 같이 시간 정보가 중요한 데이터를 다루는 데 특히 적합하다.
TSDB 방식을 지원하는 저장소로는 다음과 같은 옵션들이 있다:
- 클라우드 스토리지: Amazon S3, Google Cloud Storage(GCS) 등의 클라우드 서비스를 이용하여 로그 데이터를 저장할 수 있다. 이는 대규모 데이터 처리와 확장성이 필요한 환경에서 주로 사용된다.
- 파일 시스템: 로컬 또는 네트워크 파일 시스템을 사용하여 데이터를 저장할 수 있다. 이는 소규모 환경이나 테스트 목적으로 적합할 수 있다.
- MinIO: 오픈소스 객체 스토리지 솔루션인 MinIO를 사용하여 로그 데이터를 저장할 수 있다. MinIO는 S3 호환 API를 제공하며, 온프레미스 환경에서 클라우드와 유사한 객체 스토리지 기능을 구현할 수 있게 해 준다.
여기서 on-prem 환경, opensource, object storage를 만족해야 했으므로 minio를 사용하기로 했다.
그전에 객체 저장소란 뭐고 minio란 뭐고?
(Object Storage)는 데이터를 객체 단위로 저장하고 관리하는 스토리지 시스템입니다.
각 객체는 데이터, 메타데이터, 그리고 고유 식별자를 포함하며,
이를 통해 대규모의 비정형 데이터를 효율적으로 저장하고 검색할 수 있습니다.
MinIO는 오픈소스 객체 저장소 솔루션으로, 두 가지 주요 저장 방식을 제공합니다:
- Filesystem 모드:
- 데이터를 직접 파일 시스템에 저장합니다.
- 간단하고 직관적인 구조로, 소규모 환경이나 테스트 목적에 적합합니다.
- Erasure 모드:
- 데이터와 함께 패리티 정보를 저장합니다.
- 이 방식은 데이터 복구 기능을 제공하여 높은 내구성과 가용성을 보장합니다.
- 하드웨어 장애나 데이터 손실 시 복구가 가능하므로 중요한 데이터를 다루는 프로덕션 환경에 적합합니다.
MinIO의 이러한 저장 방식은 사용자의 요구사항에 따라 유연하게 선택할 수 있으며,
클라우드 네이티브 애플리케이션과의 호환성을 제공하여 현대적인 데이터 저장 솔루션으로 활용됩니다.
예제 구성
예제를 만들어볼 땐 아래와 같은 순서로 구성했다. 해당 블로그 글을 참고해 구성했다.
https://blog.min.io/how-to-grafana-loki-minio/
How To Deploy Grafana Loki and Save Data to MinIO
Install and configure Loki, Promtail, Grafana and MinIO to quickly get started working with log data.
blog.min.io
순서
- app 구현 (log를 만들어내는 단순 코드)
- storage 설치 (Minio)
- loki 설치 (log engine, push 방식이니까 먼저 설치)
- promtail 설치 (1번 구현된 곳에 같이)
- grafana 설치

각 모듈마다 docker에 올려서 사용했다. (이번에 처음 docker 써봤는데 진짜 신세계,,, 넘나 편하잖슴...)
app 구현
python script가 랜덤 하게 문자열을 뿜어내면서 log에 글을 쓰게 만들 거다.
일단 docker를 올려주고~~ (docker file이 아니라 실행순서닷!)
docker pull python
docker run -it
--name python_container
-v /Users/~~~~/Documents/docker_v:/docker_v python:latest
mkdir logs
apt-get update
apt-get install vim -y
python 파일 생성
import random
import string
import datetime
import time
import os
logLevel = ['ERROR', 'INFO', 'DEBUG']
now = datetime.datetime.now()
level = random.choice(logLevel)
filename = "./logs/"+level+".log"
mode = 'a' if os.path.exists(filename) else 'w'
with open(filename,mode) as f:
N = random.randrange(1,1000)
log = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(N))
f.write(str(now)+"\t"+level+"\t"+log+"\n")
해당 python 파일을 실행시켜 줄 sh 작성
#!/bin/sh
while true
do
python /docker_v/randomLog.py
sleep 1
done
올라간 뒤 확인해 보면

원하는 대로 log를 찍어내는 아름다운 모습...
network 설정
docker network create loki
storage 설치 (Minio)
docker pull minio/minio
docker run -itd\
--name minIO_container\
-v /Users/~~~~~/Documents/docker_v_minIO:/docker_v_minIO\
--network loki\
-p 9000:9000\
-p 9001:9001\
minio/minio:latest\
server ~ --address ':9000' --console-address ':9001'
접근을 위해서 port 뚫어주고~ network bridge로 연결해 주고 정상적으로 설치됐다면 localhost:9000 접속 시

minio web-ui로 접근가능하다.
loki 설치
loki를 설치하기 전에... 호스트와 볼륨마운트 된 곳에 config.yml을 미리 구성해 놓는 게 정신건강에 이롭다. (하.. 내 시간)
# config.yml
auth_enabled: false
server:
http_listen_port: 3100
common:
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
replication_factor: 1
path_prefix: /loki
schema_config:
configs:
- from: 2024-11-15
store: tsdb
object_store: aws
schema: v13
index:
prefix: index_
period: 24h
storage_config:
tsdb_shipper:
active_index_directory: /loki/index
cache_location: /loki/index_cache
aws:
s3: http://{172.18.0.2}:9000/loki
s3forcepathstyle : true
bucketnames: loki
limits_config:
reject_old_samples: true
reject_old_samples_max_age: 168h
table_manager:
retention_deletes_enabled: false
retention_period: 0s
이건 예시고 나중에 세팅할 때 필요하면 바꾸거나 추가해야 한다...
중요한 건 s3 설정 부분에 minio 주소를 적어놔야 한다!!!
혹시 모르니 참고할 예시 config.yml 파일
loki-config.yaml file ⇒ https://github.com/grafana/loki/blob/v1.6.1/cmd/loki/loki-docker-config.yaml
loki/cmd/loki/loki-docker-config.yaml at v1.6.1 · grafana/loki
Like Prometheus, but for logs. Contribute to grafana/loki development by creating an account on GitHub.
github.com
docker 올리기
docker pull grafana/loki
wget https://raw.githubusercontent.com/grafana/loki/v3.0.0/cmd/loki/loki-local-config.yaml -O loki-config.yaml
docker run -itd\
--name loki_container\
-v /Users/~~~~/Documents/docker_v_loki/production:/home/loki/production\
--network loki\
-p 3100:3100
grafana/loki:latest -config.file=/home/loki/production/loki-config.yaml -config.expand-env=true
promtail 설치
promtail의 경우, log가 생성되고 있고, 해당 로그를 loki로 보내려면 loki가 켜져 있어야 하기에 순서상 4번째이고, 세팅도 간단한 편이다
우선 log를 뿜어내는 server(여기선 python docker 내)로 이동해서
mkdir promtail && cd promtail
# promtail-linux-arm64.zip
wget https://github.com/grafana/loki/releases/download/v3.2.1/promtail-linux-arm64.zip
unzip promtail-linux-arm64.zip
# config download
wget https://raw.githubusercontent.com/grafana/loki/v3.2.1/clients/cmd/promtail/promtail-local-config.yaml
# ref)https://creampuffy.tistory.com/213
다운로드한 promtail-local-config.yaml 파일을 환경에 맞게 세팅해 준다
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://{172.18.0.4}:3100/loki/api/v1/push
scrape_configs:
- job_name: error
static_configs:
- targets:
- localhost
labels:
job: error_logs
__path__: /docker_v/logs/ERROR*.log
- job_name: debug
static_configs:
- targets:
- localhost
labels:
job: debug_logs
__path__: /docker_v/logs/DEBUG*.log
- job_name: info
static_configs:
- targets:
- localhost
labels:
job: info_logs
__path__: /docker_v/logs/INFO*.log
그리고 실행
nohup /docker_v/promtail/promtail-linux-arm64
-config.file=/docker_v/promtail/promtail-local-config.yaml > /docker_v/logs/promtail.log
2>&1 &
제대로 동작한다면

아래와 같이 로그가 쌓이기 시작한다
grafana 설치 (grafana의 default login id/pw는 admin/admin)
docker pull grafana/grafana
docker run -itd
--name grafana_container
-p 3000:3000
--network loki
grafana/grafana:latest
localhost:3000으로 들어가 보면

이제 log -> promtail -> loki -> minio 순으로 데이터가 쌓이고 있는 상황이고, grafana로 loki에 연결해서 확인해 보자.
datasource -> add new datasource -> loki 검색 -> connection 설정

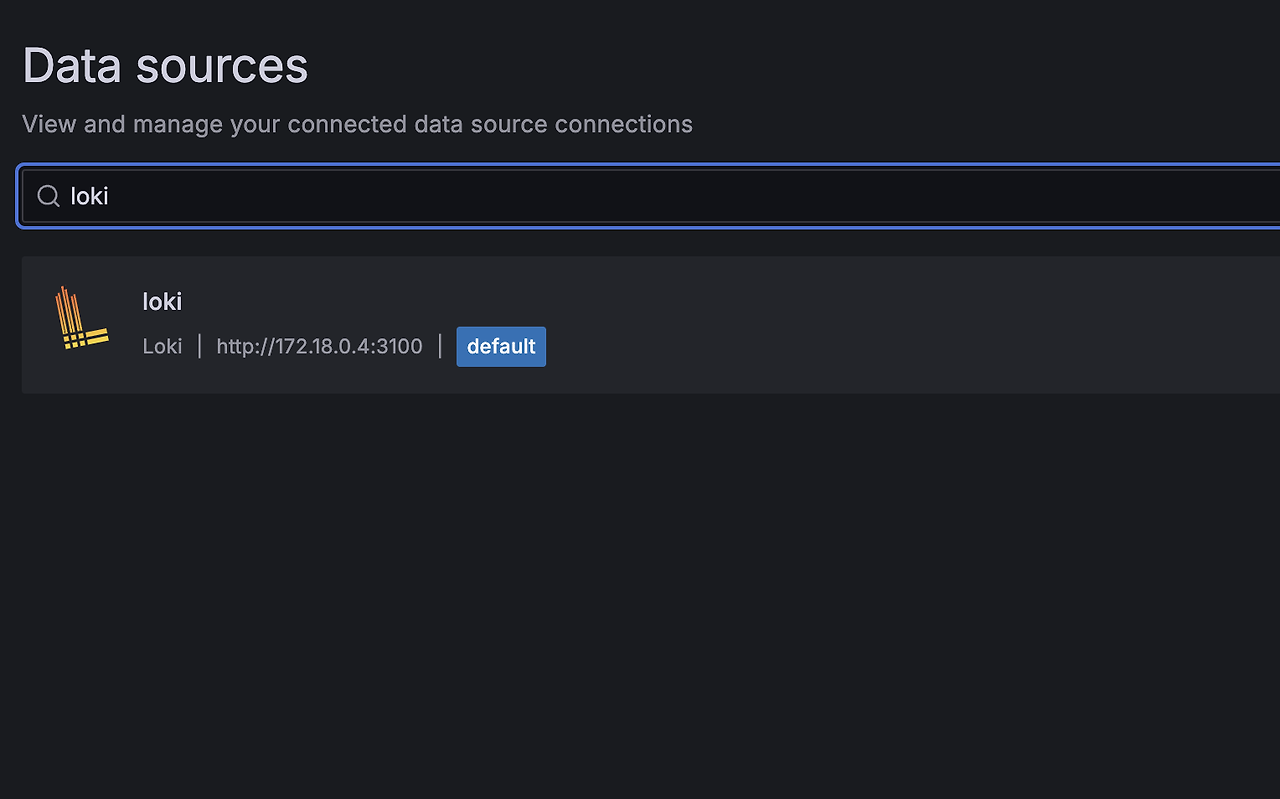

확인해 보면

잘 들어가는 걸 확인할 수 있다!!!
추가적으로 확인해 본 사항들...
agent 사용하지 말고 직접 넣을 수 있댔는데 정말인가??
python을 이용해서 api 형식으로 push 할 수 있는지 python docker에서 실험!
# example of usage grafana/loki api when you need push any log/message from your python scipt
import requests
import json
import datetime
import time
# import pytz
host = 'python-push'
curr_datetime = datetime.datetime.now() # pytz.timezone('Asia/Seoul')
curr_datetime = str(curr_datetime) #curr_datetime.isoformat('T')
msg = 'On server {host} detected error'.format(host=host)
# push msg log into grafana-loki
url = 'http://172.18.0.4:3100/loki/api/v1/push'
headers = {
'Content-type': 'application/json'
}
payload = {
'streams': [
{
'stream' :
{
"label" : '''{source=\"pushPython\",job=\"manual_push\", host=\"' + host + '\"}'''
},
'values': [
[str(time.time_ns()), '[WARN] ' + msg]
]
}
]
}
payload = json.dumps(payload)
answer = requests.post(url, data=payload, headers=headers)
print(answer.text)
response = answer
print(response)
# end pushing
# ref) https://grafana.com/docs/loki/latest/reference/loki-http-api/#ingest-logs


동작 확인~
java log4 j2 적용해서 로그 보낼 수 있다는데? 당장 해보기!
pom.xml dependency 설정
<dependencies>
<!-- log4j2 로그 추가 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.18.0</version>
</dependency>
<!-- SLF4J를 통해 log4j를 처리하고 있으므로 관련한 dependency도 추가 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.13.1</version>
</dependency>
<dependency>
<groupId>org.bgee.log4jdbc-log4j2</groupId>
<artifactId>log4jdbc-log4j2-jdbc4</artifactId>
<version>1.16</version>
</dependency>
<dependency>
<groupId>pl.tkowalcz.tjahzi</groupId>
<artifactId>log4j2-appender-nodep</artifactId>
<version>0.9.17</version>
</dependency>
</dependencies>
resources/log4j2.xml 설정
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="debug">
<Appenders>
<!-- 콜솔 -->
<Console name="console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd hh:mm:ss} %5p [%c] %m%n"/>
</Console>
<!-- loki -->
<Loki name="loki-appender">
<host>172.18.0.4</host>
<port>3100</port>
<PatternLayout>
<Pattern>%X{tid} [%t] %d{MM-dd HH:mm:ss.SSS} %5p %c{1} - %m%n%exception{full}</Pattern>
</PatternLayout>
<Label name="server" value="java-docker"/>
<Label name="job" value="java-docker-logger"/>
<Label name="service" value="java-docker-logging"/>
<Label name="job_name" value="java-docker-log-job"/>
</Loki>
</Appenders>
<loggers>
<root level="debug" additivity="true">
<AppenderRef ref="console"/>
<AppenderRef ref="loki-appender"/>
</root>
</loggers>
</configuration>
java 파일 작성
// LogTest.java
public class LogTest {
private Logger logger = LoggerFactory.getLogger(LogTest.class);
public void test() {
logger.debug("Hello Log test");
}
}
// Main.java
public class Main {
public static void main(String[] args) {
LogTest logTest = new LogTest();
logTest.test();
}
}
jar 빌드 및 docker 구성
docker pull openjdk:8-jdk-alpine
docker run -itd --name java-container
--network loki
-v /Users/jhpark/Documents/docker_v:/docker_v
openjdk:8-jdk-alpine

동작 확인~
prometheus
해당 tool은 prometheus와 생태계를 공유하는데 찾아보다가 문득... 어? 쟤네들 metrics endpoint 연결하면 상태값도 받아볼 수 있지 않을까 하는 생각이 들었다.
간략하게 prometheus 란?
- open source 모니터링 툴
- server side pull 방식으로 관찰 대상의 상태값을 당겨옴
- api endpoint로 요청해 주기적 pull 방식
같은 생태계 도구들이라 그런지 상태값을 받아오는 end point들을 prometheus에 맞게 열어두게끔 설정할 수 있게 되어있다
loki => locahost:3100/metrics
promtail => localhost:9080/metrics
# promtail_config.yaml 파일 수정
http_listen_port : 9080
loki와 마찬가지로 docker를 올리기 전 config.yml 파일을 수정해 준다.
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# - job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
# scrape_interval: 5s
- job_name : 'loki'
scrape_interval : 5s
static_configs:
- targets : ['host.docker.internal:3100']
docker를 올려주고
docker pull prom/promethus
docker run -itd
--name prometheus_container
-p 9090:9090
--network loki
-v /Users/~~~~/Documents/docker_v_prometheus:/etc/prometheus
grafana에서
datasource -> add new datasource -> prometheus -> connection {ipaddress}:9090

위와 같이 구성했을 때 구조는 아래와 같아진다

데이터의 흐름으로 살펴보면!

이런 식으로 구성했다!
이렇게 간단하게 log 관련 시스템을 찍먹 해봤다.
이제... 실제로 사용할 시간이지... 누가? 내가~
'text > common' 카테고리의 다른 글
| Docker & Registry 설치 및 문제 해결 후기 (0) | 2025.02.12 |
|---|---|
| Docker Registry를 이용해 사설 private image서버 설정 (0) | 2025.01.11 |
| mysql order by equal? (2) | 2023.12.05 |
| maven multi binding 문제 시 해결 (1) | 2023.10.12 |
| 변수 메모리 할당 (간단 정리) (0) | 2023.07.31 |



댓글