저번에 친구랑 얘기하다 나온 요즘 핫한 사건
https://news.mt.co.kr/mtview.php?no=2023021023543967230
죽은 아내가 낳은 불륜남 아기…"출생신고라도" 남편 설득하는 市 - 머니투데이
숨진 아내와 다른 남자 사이에서 태어난 아이를 산부인과에 남겨둔 법적 친부에게 청주시가 "출생신고라도 하라"고 설득하고 있는 것으로 전해졌다. 10...
news.mt.co.kr
여기 등장하는 “친생자관계부존재확인”라는 단어가 있다.
중요한 건 단어의 의미가 아니고 마침 열 글자였다는 데 있다.
마침 심심했던 찰나에 이걸보고 쓸데없는 호기심이 발동…
4 글자씩 끊어서 쳐보니 아래와 같이 나온다.

그렇게 친 글자를 세로로 연결해 새로운 글자로 만들면 전혀 다른 글자가 나오고…
그럼 이걸 몇번 반복하면 원래 글자로 나오는지가 궁금했다.
(하지만 카톡창에선 치지 않았다. 몇 번 만에 바뀌는지 알 수 없기에…)
그래서 코드로 짜보려고 한다.
단어가 입력으로 주어지면
- 4글자씩 쪼개서 저장 (일종의 2차원 배열 생성)
- 저장된 배열을 세로로 조회 (column access)
- 조회한 글자를 연결
- 본래의 입력과 같아질 때까지 반복 (반복 횟수를 세기)
로직을 세웠으니 구현을 해보자.
1. 4 글자씩 쪼개서 저장
mat = []
for i in range(0, len(test_text), 4):
mat.append(test_text[i:i+4])2. 저장된 배열을 세로로 조회 & 글자를 연결
temp_result = ""
for i in range(4):
word = ""
for j in range(len(mat)):
if len(mat[j]) > i:
word += mat[j][i]
temp_result += word3. 입력과 비교
count += 1
if temp_result == org_input:
return count
else:
test_text = temp_result
전체 코드는 다음과 같다.
text = "친생자관계부존재확인"
def letterLoop(org_input):
test_text = org_input
count = 0
while True:
mat = []
for i in range(0, len(test_text), 4):
mat.append(test_text[i:i+4])
temp_result = ""
for i in range(4):
word = ""
for j in range(len(mat)):
if len(mat[j]) > i:
word += mat[j][i]
temp_result += word
count += 1
if temp_result == org_input:
return count
else:
test_text = temp_result
print(letterLoop(text))실행 결과 (몇번 돌아가야 하는지)에 대한 결과는
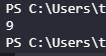
총 9번의 글자 돌리기 연산이 필요하다는걸 알 수 있다.
좀 더 발전 시켜보자. 만약 4 글자씩이 아니라면? (3 글자씩 or 5 글자씩)
함수를 수정해서 글자수에 대한 파라미터를 만든다.
def letterLoop(org_input, N=1): #-> 글자 수 입력 부분
test_text = org_input
count = 0
while True:
mat = []
for i in range(0, len(test_text), N):
mat.append(test_text[i:i+N])
temp_result = ""
for i in range(N):
word = ""
for j in range(len(mat)):
if len(mat[j]) > i:
word += mat[j][i]
temp_result += word
count += 1
if temp_result == org_input:
return count
else:
test_text = temp_resultN = 1 일 땐 글자를 가로가 아닌 세로로 만들고, 세로를 그대로 읽으니 기존의 문자열과 같고
N > 글자길이 일땐 글자 전체가 하나의 row로 저장되니 기존의 문자열과 같다.
그렇다면 1 <= N < 글자길이 일 땐 각각 결과가 어떻게 나올까?
for n in range(1, len(text)+1):
print("n = ",n,"loopcount=",letterLoop(text,n))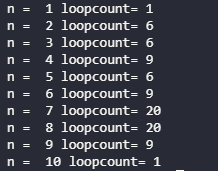
나누는 글자수가 7, 8 일 때 가장 큰 걸 확인할 수 있다.
이렇게 한 줄씩 결과를 프린트해서 확인하기보다 좀 더 가시화해보자.
차트로 보자면 (x = 나누는 글자수, y = 연산수(loop count)라고 할 때)
import matplotlib.pyplot as plt
text = "친생자관계부존재확인"
def letterLoop(org_input, N=1):
###### 기존과 동일
x = []
y = []
for n in range(1, len(text)+1):
x.append(n)
y.append(letterLoop(text, n))
plt.plot(x,y)
plt.show()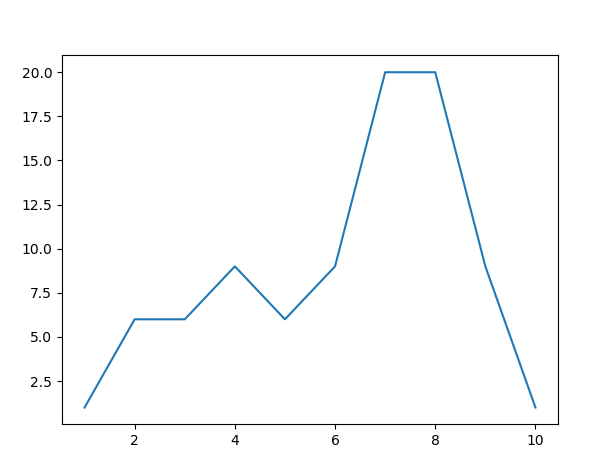
아래와 같이 7,8에서 가장 크게 나오는 걸 확인할 수 있다.
여기서 추가적으로 발전시켜 보면 입력되는 글자가 10글자가 아니라 그 이상이라면?
이번에 입력해 볼 글자는 위에 적은
“여기서 추가적으로 발전시켜 보면 입력되는 글자가 10글자가 아니라 그 이상이라면” 으로 바꿔서
확인해 보자. 입력하기 앞서 띄어쓰기를 제거해 준다.
def removeSpace(input):
return input.replace(" ","")코드는 아래와 같고
import matplotlib.pyplot as plt
text = "여기서 추가적으로 발전시켜보면 입력되는 글자가 10글자가 아니라 그 이상이라면"
def removeSpace(input):
return input.replace(" ","")
def letterLoop(org_input, N=1):
# 기존과 동일
x = []
y = []
text = removeSpace(text)
for n in range(1, len(text)+1):
x.append(n)
y.append(letterLoop(text, n))
plt.plot(x,y)
plt.show()결과는 아래와 같다.
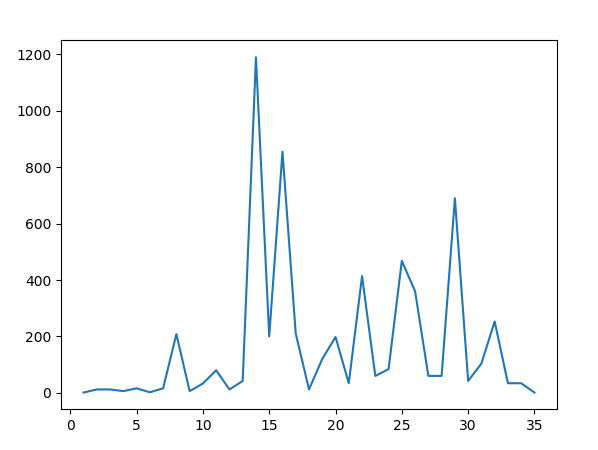
N = 14 (나누는 글자수) 일 때 무려 1200회까지 뛰는 걸 확인할 수 있다.
문제를 조금 더 일반화해보자.
M = 글자 길이, N = 나누는 글자수(N≤M), 일 때 M과 N사이에 규칙이 있을까?
M = “가나다라마바사아자차카타파하”
일 때, M의 글자를 “가”부터 “가나다라마바사아자차카타파하”까지 한 글자씩 늘렸을 때
그래프 모양을 한꺼번에 그려서 확인해 보자.
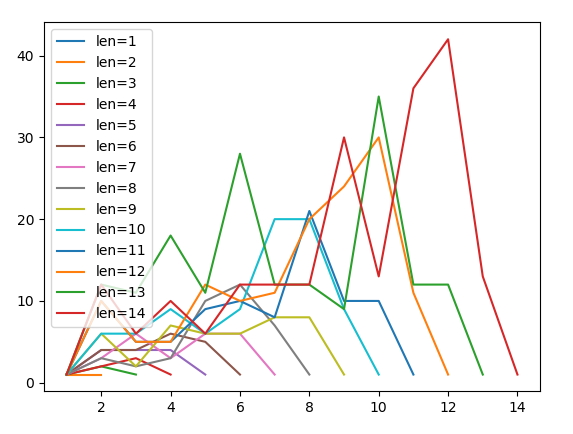
흠… 규칙은 잘 모르겠다.
여기까지 뇌절해보니 개발보다는 수학 쪽인 것 같아서 나는 이만

전체 코드는 아래와 같다.
import matplotlib.pyplot as plt
text = "가나다라마바사아자차카타파하"
def removeSpace(input):
return input.replace(" ","")
def letterLoop(org_input, N=1):
test_text = org_input
count = 0
while True:
mat = []
for i in range(0, len(test_text), N):
mat.append(test_text[i:i+N])
temp_result = ""
for i in range(N):
word = ""
for j in range(len(mat)):
if len(mat[j]) > i:
word += mat[j][i]
temp_result += word
count += 1
if temp_result == org_input:
return count
else:
test_text = temp_result
text = removeSpace(text)
for length in range(1, len(text)+1):
x = []
y = []
for n in range(1, len(text[:length])+1):
x.append(n)
y.append(letterLoop(text[:length], n))
# print("n = ",n,"loopcount=",letterLoop(text,n))
plt.plot(x,y, label="len={}".format(length))
plt.legend(loc="upper left")
plt.show()
ps. 수학전공하신 분들이 혹여 보게 되면 규칙이 있는지 알려주실 수 있을까요....
'text > Python' 카테고리의 다른 글
| python으로 간단한 In-Memory Key-Value DB 만들기 (1) | 2025.07.13 |
|---|---|
| 등수 반환 문제 고찰 (0) | 2023.10.20 |
| python 으로 구현하는 간단간단 검색엔진 로직 (1) | 2022.12.30 |
| 편집거리 알고리즘을 통한 검색어 자동완성 보정 (ft . Levenshtein Distance) (0) | 2022.11.26 |
| 브랜드 이름 검색어 자동완성 2 (with Suffix Trie) (0) | 2022.11.19 |




댓글