저번 검색어 자동완성 글 말미에 오타가 들어가 있는 경우, 제대로 된 단어로 유추될 수 있으면 좋겠다는 생각을 했는데 마침 적당한 알고리즘이 있어서 실제로 실습해봤다.
브랜드 이름 검색어 자동완성 2 (with Suffix Trie)
저번 Trie를 이용한 검색 자동완성의 연장선의 글이다. 브랜드 이름 검색어 자동완성 with Trie 브랜드 이름 검색어 자동완성 with Trie 인터넷을 돌아다니다 글을 하나 보게 됐다. 카테고리 자동완성
hoonzi-text.tistory.com
레벤 슈타인 알고리즘이라고… 이름부터 어렵지만 막상 까 보면 생각보다 별거 없는 알고리즘이 있다.
두 문자열이 얼마나 다른지 값으로 나타내주는 알고리즘으로
- 문자를 삽입, 삭제, 치환하여 다른 문자열로 변형하는데 필요한 최소 횟수
- 철자 검사기 등에서 두 문자열이 어느 정도 유사한지 값으로 나타내는 방법의 하나
- 1965년 러시아의 브라디미르 레벤 슈타인이 고안함
- 같으면 0, 다르면 1 이상
위와 같은 특징을 가지고 있다.
출처 : https://zetawiki.com/wiki/레벤슈타인_거리
그럼 어떻게 두 문자열이 다른지 알아내냐?
S: 원래 스트링 T: 비교 스트링이라 했을 때 S -> T로 변환하는데 필요한
삽입, 삭제, 대치 연산의 최소 비용(최소 편집 횟수)을 구함으로써 판단한다.
(비용이 작게 나올수록 유사도가 큼)
식은 아래와 같이 쓴다.(고 한다.)

머.. 이런 거 난 잘 모르겠고, 정리하자면
(출처 : https://renuevo.github.io/data-science/levenshtein-distance/ )
두 단어의 길이로 된 행렬을 만들고
삽입이 필요 : 현재 칸의 왼쪽 값 + 1
삭제가 필요 : 현재 칸의 위쪽 값 + 1
수정이 필요 : 현재 칸의 대각선 값 + 1
만약 adiddas → adidas로 변환한다면 “d” 하나만 삭제하면 되므로 편집 거리는 1 이 된다.
행렬로 표현해보자.
빈 문자열과 각 문자들 간의 편집거리는 문자 길이만큼이므로 먼저 값을 채워준다.
adidas의 a와 adiddas를 비교했을 때 모습
a / ad → d가 하나 추가되므로 min(위, 옆, 대각선 값) + 1 = 0 + 1 = 1
a / adidda → a 가 같으므로 대각선 값을 그대로 가져오기 = 5
계속 진행해보면
행렬의 마지막 부분이 두 단어의 편집 거리의 최종 값이다.
adidas와 adiddas의 최종 편집 거리는 1로 이걸 코드로 옮겨보자.
text = "adidas"
compare_text_list = ["adiddas", "adidus","addiss","dadiffs"]
def levDistance(text1, text2):
row_len = len(text1)+1
col_len = len(text2)+1
mat = [[0 for n in range(col_len)] for r in range(row_len)]
for i in range(row_len):
mat[i][0] = i
for j in range(col_len):
mat[0][j] = j
for i in range(1, row_len):
for j in range(1, col_len):
a = text1[i-1]
b = text2[j-1]
match = 0 if a == b else 1
replace = mat[i-1][j-1] + match
insert = mat[i-1][j] + 1
delete = mat[i][j-1] + 1
mat[i][j] = min(replace, insert, delete)
return mat[-1][-1]
for compare in compare_text_list:
print(text, compare, levDistance(text, compare))
위 예시 행렬과 동일한 결과가 나온 걸 확인할 수 있다.
더 자세한 설명은 아래의 링크에서 확인하자.. (솔직히 아래의 블로그 글이 더 잘 설명했다.)
https://renuevo.github.io/data-science/levenshtein-distance/
[DataScience] Levenshtein Distance (편집거리 알고리즘) - 문장 유사도 분석을 어떻게 하는가?
Levenshtein Distance (편집거리 알고리즘) 는 러시아의 과학자 블라디미르 리벤슈테인가 고안한 알고리즘 Levenshtein Distance이 무엇일까? 오늘날 언어학/데이터과학 같이 폭 넓게 사용되고 있으며 문장
renuevo.github.io
이 함수를 이전 suffix Trie에 추가해보자.
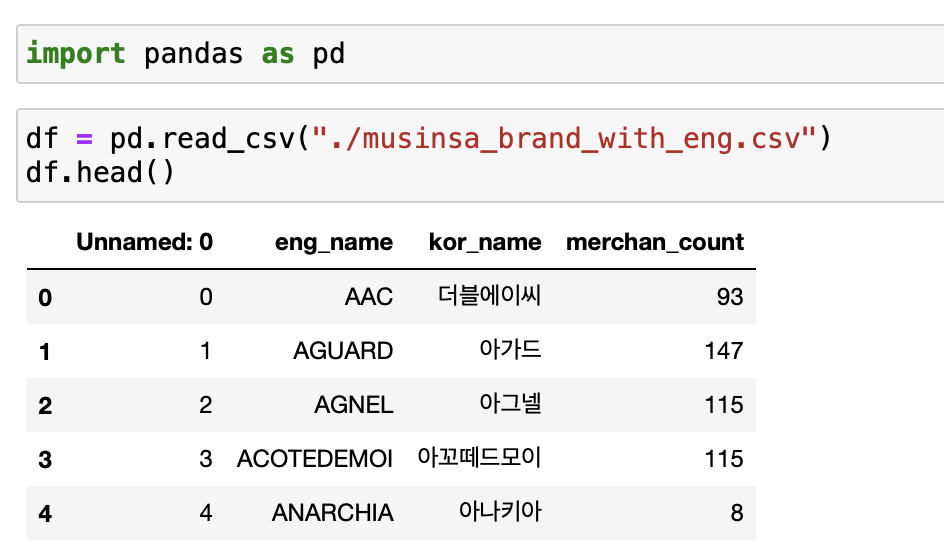
먼저 데이터를 불러와 주고…
위에서 정의한 함수를 선언해준다.
def levDistance(text1, text2):
row_len = len(text1)+1
col_len = len(text2)+1
mat = [[0 for n in range(col_len)] for r in range(row_len)]
for i in range(row_len):
mat[i][0] = i
for j in range(col_len):
mat[0][j] = j
for i in range(1, row_len):
for j in range(1, col_len):
a = text1[i-1]
b = text2[j-1]
match = 0 if a == b else 1
replace = mat[i-1][j-1] + match
insert = mat[i-1][j] + 1
delete = mat[i][j-1] + 1
mat[i][j] = min(replace, insert, delete)
return mat[-1][-1]
levDistance("adidas","adiddas") // 결과는 1이전 블로그 글의 Node 클래스와 Trie 클래스를 선언하는데 달라지는 부분은 Trie 클래스의 편집 거리 추가 부분이다.
class Trie:
...
def query(self, text):
text = text.lower()
curr = self.head
for t in text:
if t not in curr.children:
self.suggest(curr, text) # 노드를 타고 들어가다 발견하지 못하면(ex.오타)
break
else:
curr = curr.children[t]
data = {}
data["prefix_result"] = curr.prefix_data[::-1]
data["suffix_result"] = curr.suffix_data[::-1]
return data
# 오타와 가장 비슷한 단어를 현재 노드의 단어중 고르기
def suggest(self, node, text):
candidate_ = node.prefix_data[::-1]
lev_list = []
for can_text in candidate_:
lev_distance = levDistance(can_text[0].lower(), text.lower())
lev_list.append((can_text[0], lev_distance))
lev_list = sorted(lev_list, key=lambda x : x[1])
print("do you mean \\"{}\\" ?".format(lev_list[0][0]))
위 코드가 잘 동작하는지 테스트해보자.
먼저 데이터를 삽입하고
trie = Trie()
for i, rows in df.iterrows():
eng_name = rows['eng_name']
merchan_count = rows['merchan_count']
eng_name_token_list = nameTokenize(eng_name)
trie.prefix_insert(eng_name, merchan_count)
for eng_name_token in eng_name_token_list[1:]:
trie.suffix_insert(eng_name_token, eng_name, merchan_count)“adidaas”를 검색해보자.
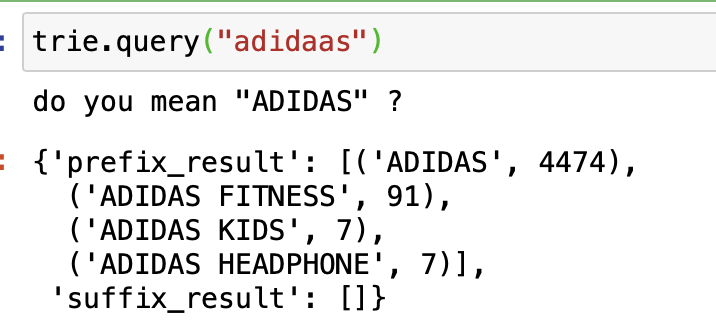
오…
한글에 대해서도 동작 하나 보자.
한글의 경우, 이전 글에서 적어 놨듯이 자모음이 순차적으로 검색되기 때문에 분해가 필요하다.
from jamo import h2j, j2hcj, j2h, j2hcj
def return_brand_name_with_jamo(text):
return_value = ""
for t in text:
jamo_list = j2hcj(h2j(t))
if len(jamo_list) == 2:
return_value += jamo_list[0]
return_value += j2h(*jamo_list)
else:
return_value += jamo_list[0]
for i in range(2,len(jamo_list)+1):
han = j2h(*jamo_list[:i])
return_value += han
return return_value
text = "아디다스"
return_brand_name_with_jamo(text)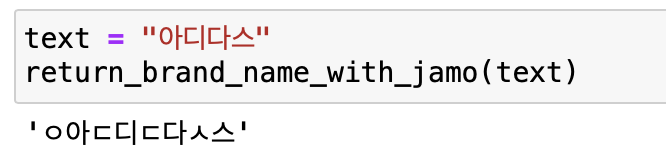
해당 자모음 분해 문자열을 넣는 함수, 검색 함수를 Trie 클래스에 만들어 넣어준다.
class Trie:
...
def prefix_kor_insert(self, kor_name, merchan_count):
text = return_brand_name_with_jamo(kor_name)
curr = self.head
for t in text:
if t not in curr.children:
curr.children[t] = Node()
curr = curr.children[t]
curr.prefix_data_insert(kor_name, merchan_count)
def query_kor(self, text):
kor_text = return_brand_name_with_jamo(text)
return self.query(kor_text)
def query(self, text):
text = text.lower()
curr = self.head
for t in text:
if t not in curr.children:
self.suggest(curr, text) # 노드를 타고 들어가다 발견하지 못하면(ex.오타)
break
else:
curr = curr.children[t]
data = {}
data["prefix_result"] = curr.prefix_data[::-1]
data["suffix_result"] = curr.suffix_data[::-1]
return data
# 오타와 가장 비슷한 단어를 현재 노드의 단어중 고르기
def suggest(self, node, text):
candidate_ = node.prefix_data[::-1]
lev_list = []
for can_text in candidate_:
lev_distance = levDistance(can_text[0].lower(), text.lower())
lev_list.append((can_text[0], lev_distance))
lev_list = sorted(lev_list, key=lambda x : x[1])
print("do you mean \\"{}\\" ?".format(lev_list[0][0]))
넣고 테스트해보자.
trie = Trie()
for i, rows in df.iterrows():
kor_name = rows['kor_name']
merchan_count = rows['merchan_count']
kor_name_token_list = []
kor_suffix = nameTokenize(kor_name)
for suffix in kor_suffix:
kor_name_token_list.append(return_brand_name_with_jamo(suffix))
trie.prefix_kor_insert(kor_name, merchan_count)
for kor_name_token in kor_name_token_list[1:]:
trie.suffix_insert(kor_name_token, kor_name, merchan_count)

오… 오타에 동작하는 구만!
하지만 엄청난 결점을 발견했다. Trie의 경우, 앞 단어부터 검색하기 때문에
“아다디스” 같은 단어의 경우 “ㅇ아ㄷ다…” 식으로 타고 내려간다. 그래서

아디다스가 아니라 아담스가 먼저 나오게 되는데 이건 내가 원하던 결과가 아니다..
그래서 레벤 슈타인 알고리즘에 “전치” 가 추가된 알고리즘이 있는데 이름은
Damerau-Levenshtein distance - Wikipedia
Damerau–Levenshtein distance - Wikipedia
In information theory and computer science, the Damerau–Levenshtein distance (named after Frederick J. Damerau and Vladimir I. Levenshtein[1][2][3]) is a string metric for measuring the edit distance between two sequences. Informally, the Damerau–Leven
en.wikipedia.org
위 레벤슈타인 알고리즘에
앞 뒤 글자를 바꿨을 때 값이 최소면 해당 값을 가져다 +1 해준다.
코드는 아래와 같다.
text = "adidas"
compare_text_list = ["adidus","addiss","dadiffs", "adiads"]
def levDistance(text1, text2):
row_len = len(text1)
col_len = len(text2)
mat = [[0 for n in range(col_len)] for r in range(row_len)]
for i in range(row_len):
mat[i][0] = i
for j in range(col_len):
mat[0][j] = j
for i in range(1, row_len):
for j in range(1, col_len):
a = text1[i-1]
b = text2[j-1]
cost = 0 if a == b else 1
replace = mat[i-1][j-1] + cost
insert = mat[i-1][j] + 1
delete = mat[i][j-1] + 1
mat[i][j] = min(replace, insert, delete)
# 추가된 부분
if j > 1 and j-1 < len(text1) and i > 0 and i-1 < len(text2):
if text1[i] == text2[j-1] and text1[i-1] == text2[j]:
mat[i][j] = min(mat[i-1][j-1], mat[i-2][j-2]+cost)
# for i in range(row_len):
# print(mat[i])
return mat[-1][-1]
# levDistance("유사도나 분석 할까요", "얼마나 분석이 될까요")
for compare in compare_text_list:
print(text, compare, levDistance(text, compare))
그렇지만 이 방법은 문자열과 문자열을 직접 비교할 때 말곤 사용할 수 없다.
이번 경우는 “아다디스” → “아디다스”인데 이미 “아다..” 로 나온 문자 열중엔 아디다스가 나올 수 없으므로
결과는 동일하다.
근데 이제 Trie 가지고 검색어 자동완성 글 적는 게 약간 지겨워져서 글은 여기까지!
'text > Python' 카테고리의 다른 글
| 심심해서 해본 글자 돌리기 (0) | 2023.02.20 |
|---|---|
| python 으로 구현하는 간단간단 검색엔진 로직 (1) | 2022.12.30 |
| 브랜드 이름 검색어 자동완성 2 (with Suffix Trie) (0) | 2022.11.19 |
| 브랜드 이름 검색어 자동완성 with Trie (1) | 2022.11.07 |
| 점진적 뉴스 군집화 하기 (incremental news clustering) (1) | 2022.06.06 |




댓글