인터넷을 돌아다니다 글을 하나 보게 됐다.
카테고리 자동완성 개발기
안녕하세요. 29CM 발견스쿼드에서 백엔드개발을 담당하고 있는 이동권입니다. 검색페이지에서 카테고리 자동완성 기능을 개발한 경험을 공유합니다.
medium.com
어느 쇼핑몰의 검색어 자동완성에 대한 글을 봤다.
간단히 요약하자면, Trie 자료구조를 이용해 단어를 저장하고, 검색 시 조건에 맞는 단어를 보여 준다는 글이다.
다 읽고, ‘오 이정도면 한번 구현해볼 만 한데?’ 싶어서 작업에 들어갔다.
대략 순서는 이렇다.
- 데이터 수집
- Trie 자료구조에 저장
- 결과를 반환해줄 api , html 페이지 구성
<데이터 수집>
글을 읽은 것과 코딩을 시작한건 시간차가 좀 있다. 그래서 그런지 저 기술 블로그가 ‘무신사’라고 착각해
데이터를 무신사에서 가져왔다. 저 기술블로그 글에선 상품 카테고리를 통해 진행했지만
무신사 내 브랜드 목록이 전부 나와있는 페이지가 있어서 해당 페이지에서 데이터를 가져왔다.
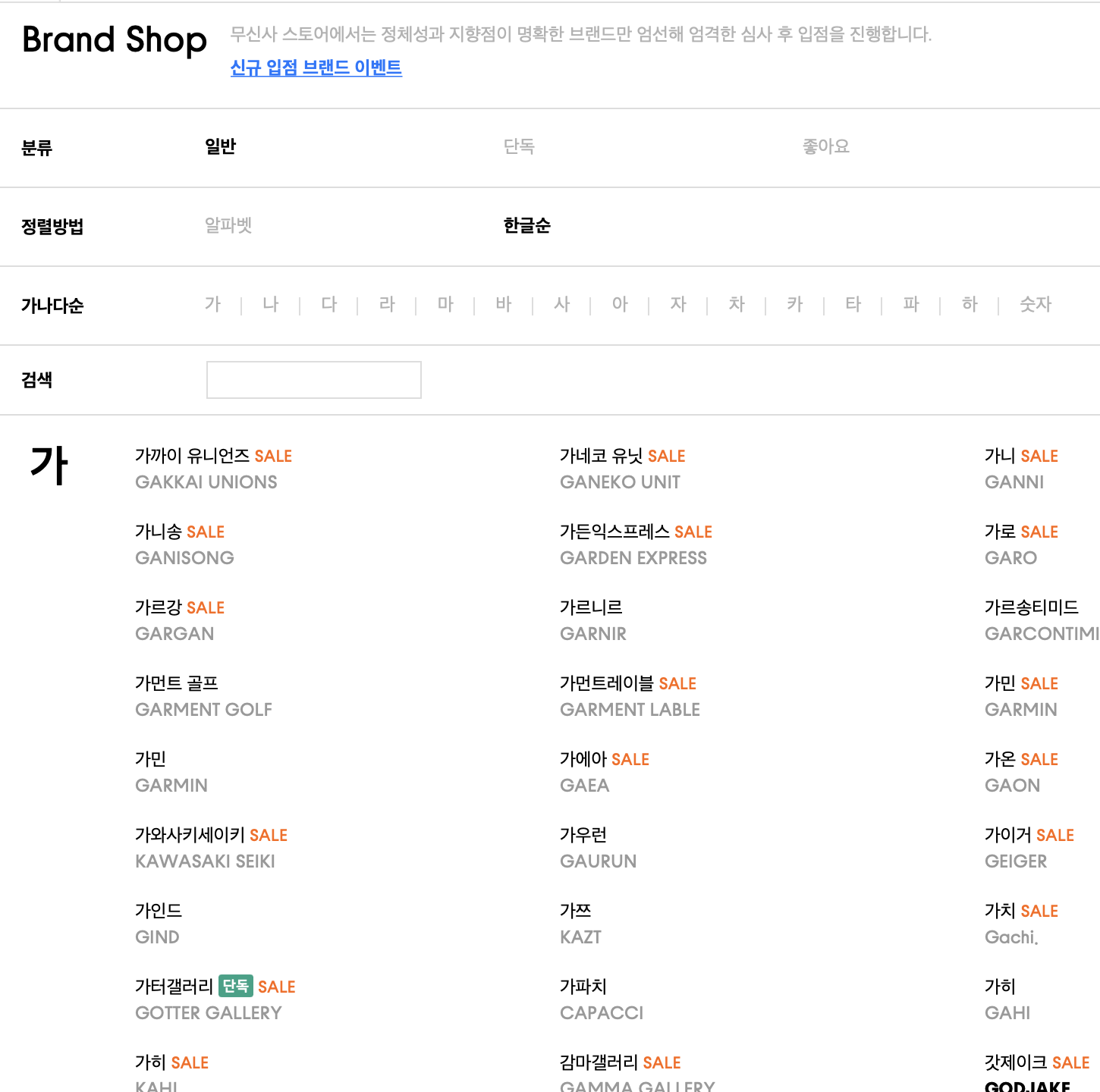
위 스크린 샷에 보이는 브랜드 이름 (한국어명, 영어명)을 가져와 준다.
import requests
from bs4 import BeautifulSoup
url = "https://www.musinsa.com/app/contents/brandshop?lang=kor"
headers = {
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15"
}
response = requests.get(url, headers = headers)
soup = BeautifulSoup(response.text, "html.parser")
brand_list = []
for li in soup.find_all("li",{"class":"brand_li"}):
dl = li.find("dl")
a = dl.find_all("a")
kor_name = a[0].text
eng_name = a[1].text
temp_dict = {
"kor_name" : kor_name,
"eng_name" : eng_name
}
brand_list.append(temp_dict)
import pandas as pd
df.to_csv("./musinsa_brand.csv") # 잊지 않고 저장해준다.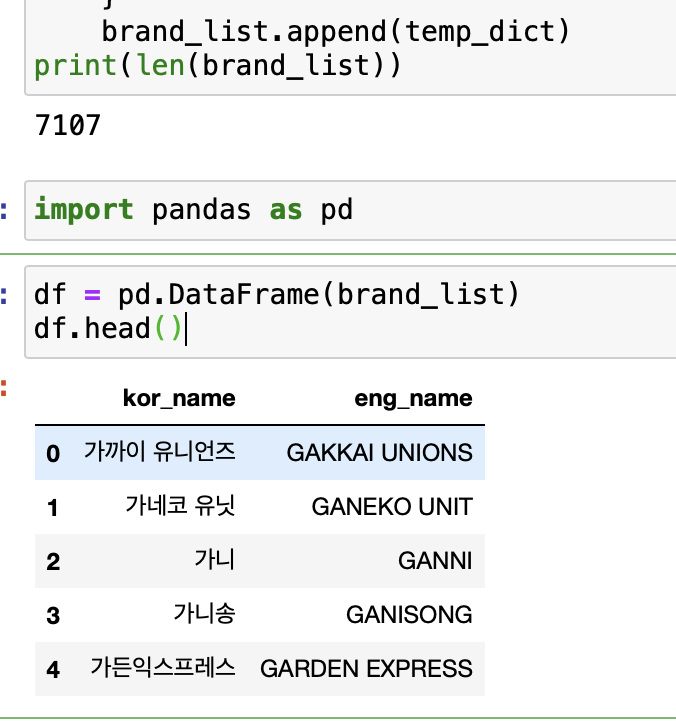
대략 7천개의 브랜드가 존재하는 걸 볼 수 있다.
<Trie 구성>
이제 Trie 자료구조에 저장해준다.
해당 자료구조에 관해서는 이전에 작성한 글[https://hoonzi-text.tistory.com/101]에 정리해뒀지만,
간단히 사진으로 보자면
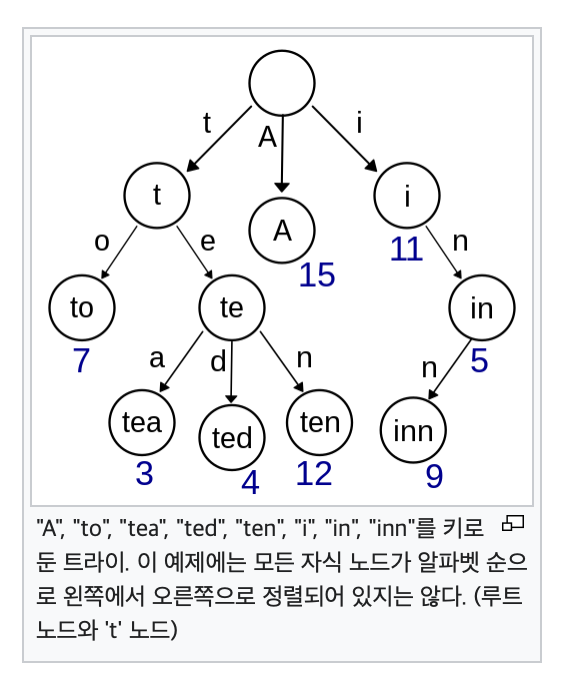
단어를 토큰 단위로 쪼개 트리에 저장 함으로써,
단어 검색시 속도를 조금 줄여 줄 수 있는 자료구조라고 보면 될듯하다.
각 노드 별로 단어의 음절과, 해당 음절이 들어간 단어를 저장하기 위해 클래스를 만들어준다.
class Node:
def __init__(self, key, data=None):
self.key = key
self.data = []
self.children = {}
# 맨처음 노드는 아무것도 저장하지 않는 head 노드를 하나 만들어준다.
head = Node(None)
단어(브랜드) 리스트를 순회하면서 하나씩 head에 추가해준다.
for brand in brand_list:
kor_name = brand["kor_name"]
current_node = head
for kor in kor_name:
if kor not in current_node.children:
current_node.children[kor] = Node(kor)
current_node.children[kor].data.append(kor_name)
else:
current_node.children[kor].data.append(kor_name)
current_node = current_node.children[kor]
코드로 보면 먼가 싶을 수 있지만, 글로 표현해 적어보면
“까르띠에"라는 단어가 들어오면 “까” → “르” → “띠” → “에” 한 음절씩 순회하면서 데이터를 아래와 같은 구조로 저장한다.
{
"key" : "None",
"data" : [],
"children" : {
"까" : {
"data" : ["까르띠에"],
"children" : {
"르" : {
"data" : ["까르띠에"],
"children" : {
"띠" : {
...
}
}
}
}
}
}
}
사용자가 검색창에 “까르” 라고 입력 시 Trie에서 조회는 아래와 같이
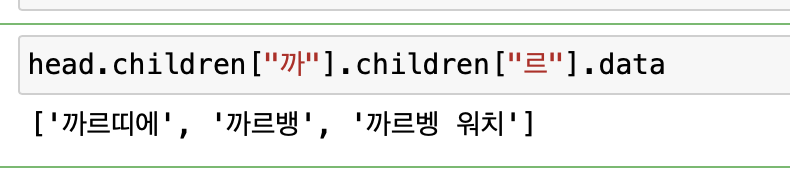
children을 타고 순회하면서 해당 단어를 접두사로 하는 단어들을 조회해준다.
<api, html 구성>
이제 위에서 수집한 데이터(./musinsa_brand.csv )
Trie 자료구조에 대한 이해를 바탕으로 눈으로 볼 수 있게 구성해보자.
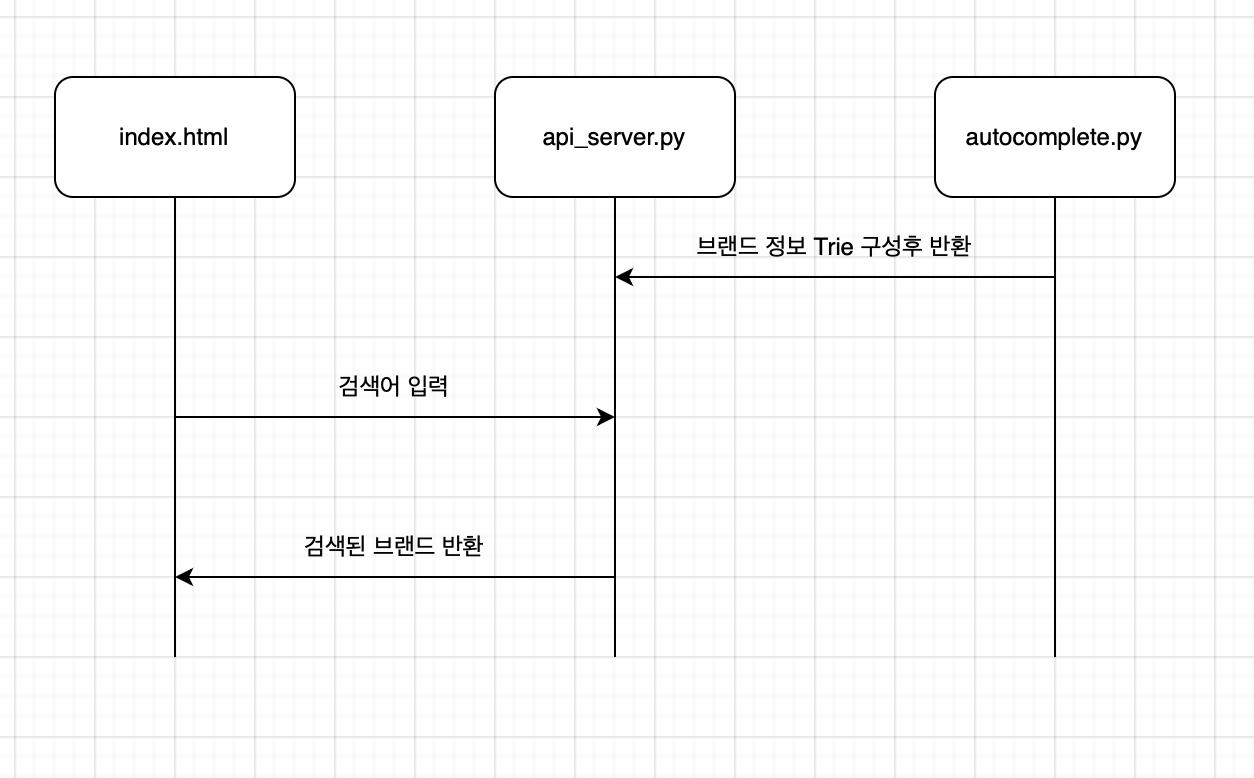
간단하게 저번에 구성은 이렇다.
- index.html
- 검색창 <input> 존재
- autocomplete.py
- csv 파일을 읽고 Trie 자료구조로 구성
- api_server.py
- fastAPI 서버 구동
ref) FastAPI document
- fastAPI 서버 구동
FastAPI
FastAPI FastAPI 프레임워크, 고성능, 간편한 학습, 빠른 코드 작성, 준비된 프로덕션 문서: https://fastapi.tiangolo.com 소스 코드: https://github.com/tiangolo/fastapi FastAPI는 현대적이고, 빠르며(고성능), 파이썬
fastapi.tiangolo.com
먼저 index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://code.jquery.com/jquery-3.6.1.min.js" integrity="sha256-o88AwQnZB+VDvE9tvIXrMQaPlFFSUTR+nldQm1LuPXQ=" crossorigin="anonymous"></script>
<style>
.parent {
display: grid;
place-items: center;
}
</style>
</head>
<body>
<div class="parent">
<h3>brand name search</h3>
<input name="brand_search" id="search"/>
<ul id="brand_list">
</ul>
</div>
</body>
<script>
$.support.cors = true;
$("#search").on("propertychange change keyup paste input", function() {
let text = $(this).val();
console.log(text)
if(text !== "")
get_list(text)
});
function get_list(keyword){
let url = "http://localhost:8000/api/"
$.ajax({
url: url, // 클라이언트가 HTTP 요청을 보낼 서버의 URL 주소
data: { q: keyword }, // HTTP 요청과 함께 서버로 보낼 데이터
method: "GET", // HTTP 요청 메소드(GET, POST 등)
dataType: "json" // 서버에서 보내줄 데이터의 타입
})
// HTTP 요청이 성공하면 요청한 데이터가 done() 메소드로 전달됨.
.done(function(json) {
let dataList = json.brand
$("#brand_list").empty();
for(let brand of dataList) {
let name = brand[0]
let count = brand[1]
$("#brand_list").append("<li>"+name+"("+count+")"+"</li>");
}
$("#brand_list").show();
})
}
</script>
</html>
<script> 태그에 적힌 js의 동작을 서술해보자면
$.support.cors = true; // cors 정책에 안부딪히게 설정
$("#search").on("propertychange change keyup paste input", function() {
let text = $(this).val();
console.log(text)
if(text !== "")
get_list(text)
});검색창에 입력될 때마다 api에 요청하는 방식으로 구성했다. (실무에선 이렇게 하면 안 되겠지…)
가→르->... 식으로 입력될 때마다 api 요청해 해당 단어에 맞는 검색 결과를 받아오는 역할이다.
function get_list(keyword){
let url = "http://localhost:8000/api/"
$.ajax({
url: url, // 클라이언트가 HTTP 요청을 보낼 서버의 URL 주소
data: { q: keyword }, // HTTP 요청과 함께 서버로 보낼 데이터
method: "GET", // HTTP 요청 메소드(GET, POST 등)
dataType: "json" // 서버에서 보내줄 데이터의 타입
})
// HTTP 요청이 성공하면 요청한 데이터가 done() 메소드로 전달됨.
.done(function(json) {
let dataList = json.brand
$("#brand_list").empty();
for(let brand of dataList) {
let name = brand
$("#brand_list").append("<li>"+name+"</li>");
}
$("#brand_list").show();
})
}api에 실제 요청하는 함수 부분이다. 쿼리 q를 날려 반환되는 값을 brand_list에 그려주는 함수이다.
autocomplete.py 파일
import pandas as pd
class Node:
def __init__(self, key, data=None):
self.key = key
self.data = []
self.children = {}
def returnTrie():
df = pd.read_csv("./musinsa_brand.csv")
brand_list = df.iterrows()
head = Node(None)
for i, brand in brand_list:
kor_name = brand["kor_name"]
current_node = head
for kor in kor_name:
if kor not in current_node.children:
current_node.children[kor] = Node(kor)
current_node.children[kor].data.append(kor_name)
else:
current_node.children[kor].data.append(kor_name)
current_node = current_node.children[kor]
return head
파일을 읽고 해당 파일에서 브랜드 이름으로 Trie를 구성한 후 반환해주고 있다.
api_server.py를 살펴보자.
from typing import Union
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
origins = [
"*"
]
import autocomplete
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
head = autocomplete.returnTrie()
@app.get("/api/")
def return_value(q: Union[str, None] = None):
print(q)
if q is None:
return None
else:
current = head
for key in q:
if key in current.children:
current = current.children[key]
else:
break
return {"brand" : current.data}
간단하다. api_server.py 구동 시 autocomplete의 Trie를 반환받고, 메모리 위에 올라가 있는 노드에
get 요청 시 Trie를 뒤져 해당 결과를 반환한다.
결과를 살펴보자.

서버를 먼저 켜준다. uvicorn {파일 이름}:app --reload
의도한 대로 동작하는 걸 확인할 수 있다.
<발전시키기>
위 동영상에서 보다시피 결과를 보고 나니 문득 생각난 것!
첫 번째
한글은 초성, 중성, 종성으로 이뤄져 있고 무신사는 “ㄱ”으로 입력해도 결과를 보여준다는 것이 기억이 났다.
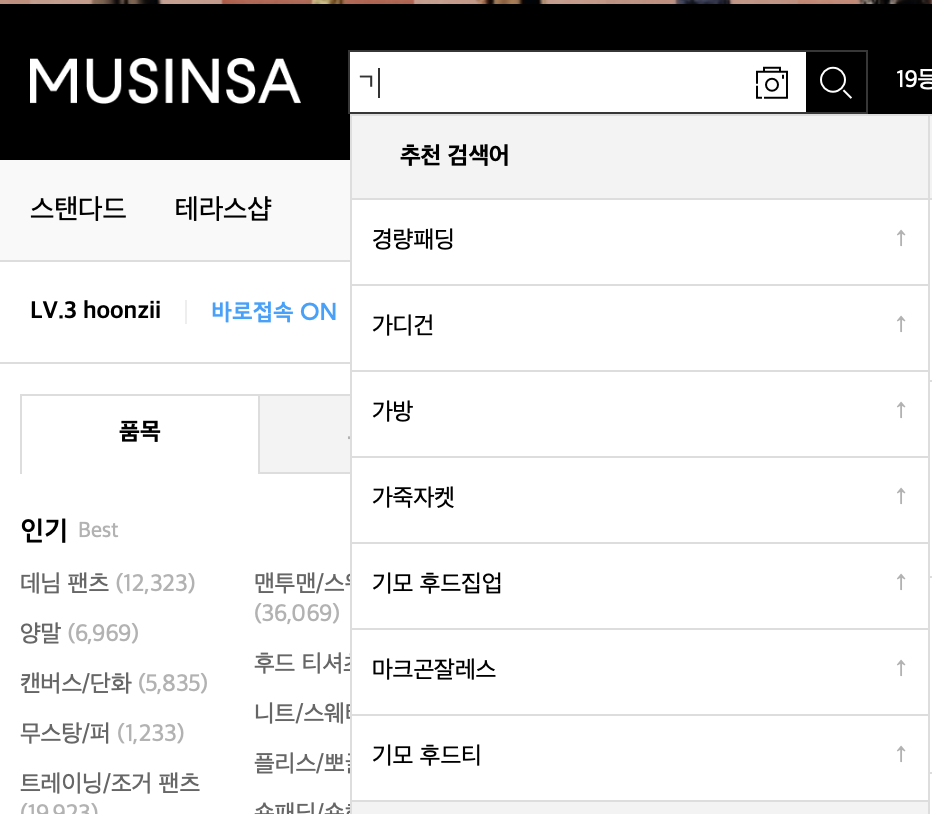
그렇다면 단어를 음절 단위가 아니라 자모음 단위로 쪼개야 하는데…
자판에 한글을 입력하고 완성되는 순서를 생각해보자
까르띠에의 경우, ㄲ까ㄹ르ㄸ띠ㅇ에 순으로 완성된다. 그럼 검색창에 검색어 역시 저렇게 구성이 될 텐데,
브랜드 이름을 자모 단위로 쪼갤 수 있어야 한다.
https://github.com/JDongian/python-jamo
GitHub - JDongian/python-jamo: Hangul syllable decomposition and synthesis using jamo.
Hangul syllable decomposition and synthesis using jamo. - GitHub - JDongian/python-jamo: Hangul syllable decomposition and synthesis using jamo.
github.com
이미 누군가 기갈나게 만들어 놓은 패키지가 있고, install 해 사용해보자. (자세한 사용법은 위 주소 참고)
from jamo import h2j, j2hcj
text = "가르강"
return_value = ""
for t in text:
jamo_list = j2hcj(h2j(t))
if len(jamo_list) == 2:
return_value += jamo_list[0]
return_value += j2h(*jamo_list)
else:
return_value += jamo_list[0]
for i in range(2,len(jamo_list)+1):
han = j2h(*jamo_list[:i])
return_value += han
return_value # output : 'ㄱ가ㄹ르ㄱ가강'단어는 초성+중성+종성 이렇게 3파트로 구성되어 있는데 받침이 없는 경우 종성이 없으므로
jamo 패키지에 의해 분해되는 결과가 길이가 2인 경우(ex. “가” → [”ㄱ”, ”ㅏ”])
“ㄱ가” 로 반환되게끔
분해되는 결과가 3인 경우(ex. “강” → [”ㄱ”, “ㅏ”, “ㅇ”])
“ㄱ가강”으로 반환되게끔 구성한다.

위에서 생각한 대로 잘 나온 걸 확인할 수 있다.
두 번째
검색 시에 상단에 보이는 순서도 역시 중요하다. 무엇이 제일 먼저 노출되어야 할까?
29cm 기술 블로그에 보면
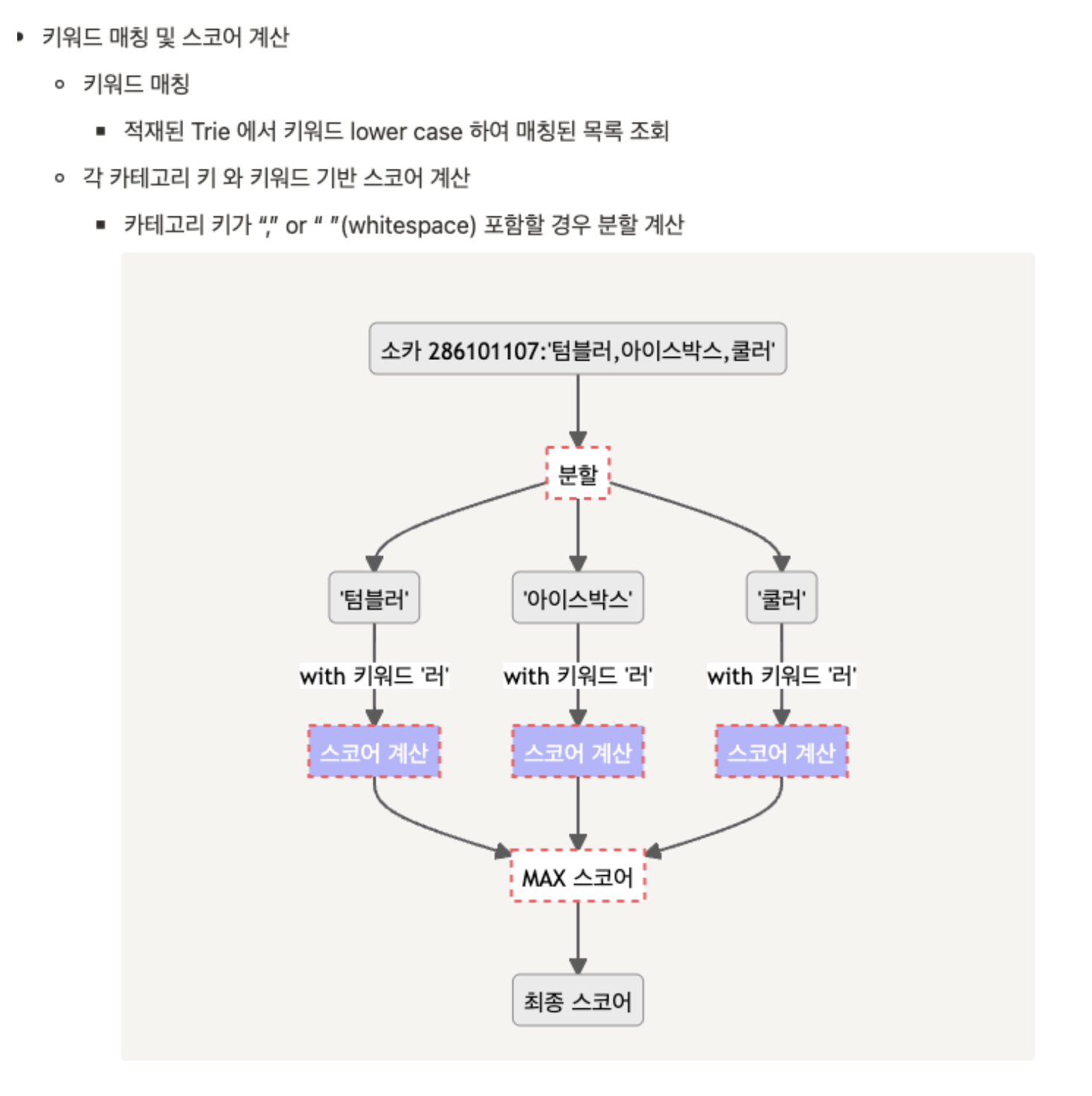
이런 식으로 스코어를 계산한다고만 되어있지 어떤 로직으로 동작하는지 까지 구체적으로 적혀있지 않기에
나는 조금 더 편한 방식으로 구현하기로 했다.
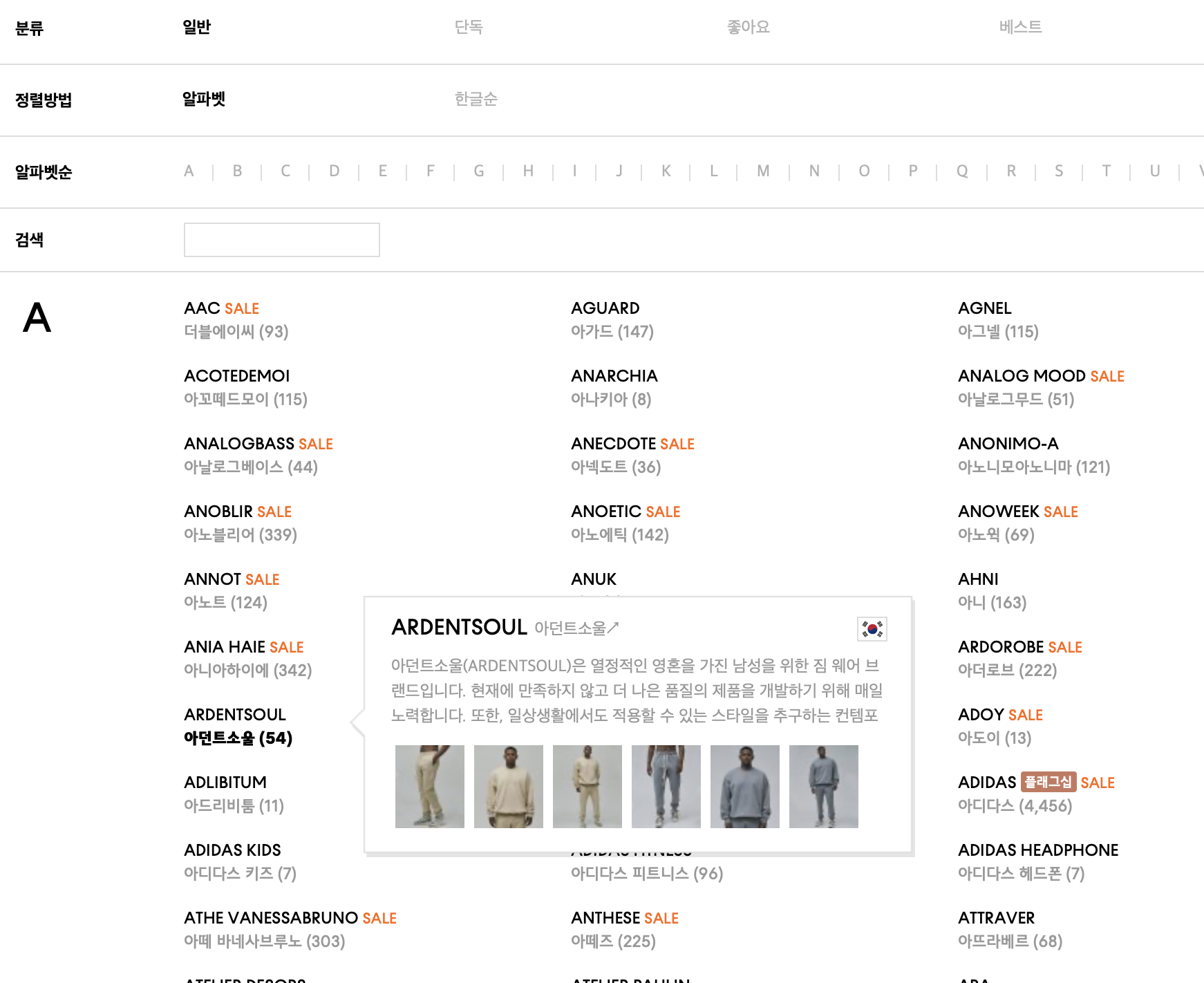
무신사의 브랜드를 “한글 순” 이 아닌 “알파벳” 순으로 정렬할 경우,
한글 브랜드 이름 옆으로 입점된 상품의 개수를 볼 수 있는데, 이걸 스코어로 사용하기로 했다.
다시 말해 상품이 많은 순으로 해서 결괏값을 보여주겠다는 얘기다.
세 번째
영어 이름, 초성 검색으로도 검색이 되게끔 Trie에 넣는 작업이 필요하다.
아디다스의 경우, “ㅇ아ㄷ디ㄷ다ㅅ스” 의 순으로 입력 시 검색되는 것 말고도,
“ㅇㄷㄷㅅ”로도 검색이 되어야 하는데, 친구(비전공자)가 듣더니
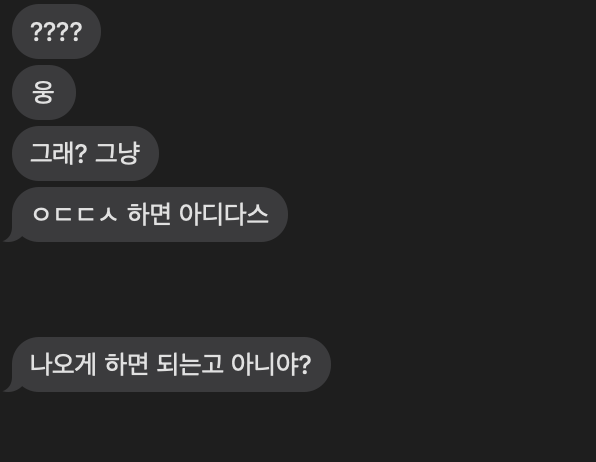
쉬운 길이 있었구먼… 아래와 같은 구조로 진행 시 단어 검색 말고도 초성으로도 검색이 가능할 것이다.
{
"key" : "None",
"data" : [],
"children" : {
"ㅇ" : {
"data" : ["아디다스"],
"children" : {
"아" : {
"data" : ["아디다스"],
"children" : {
"ㄷ" : {
...
}
}
},
"ㄷ" : { <---- 추가된 부분
"data" : ["아디다스"],
"children" : {
"ㄷ" : {
...
}
}
}
}
}
}
}
우선 수정된 사항을 반영하기 위해 데이터를 다시 수집해준다.
url = "<https://www.musinsa.com/app/contents/brandshop?lang=eng&interest_yn=N>"
headers = {
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15"
}
response = requests.get(url, headers = headers)
soup = BeautifulSoup(response.text, "html.parser")
brand_list = []
for li in soup.find_all("li",{"class":"brand_li"}):
dl = li.find("dl")
dt = dl.find("dt")
eng_name = dt.find('a').text
dd = dl.find("dd")
kor_name = dd.find('a').text
merchan_count = dd.find('span').text
kor_name = kor_name.replace(merchan_count,"").strip()
merchan_count = merchan_count.replace("(","").replace(")","").replace(",","").strip()
item = {
"eng_name" : eng_name,
"kor_name" : kor_name,
"merchan_count" : int(merchan_count)
}
brand_list.append(item)
import pandas as pd
df = pd.DataFrame(brand_list)
df.to_csv("./musinsa_brand_with_eng.csv") # 잊지 않고 저장하기!
Trie를 반환하던 autocomplete.py 를 수정해보자.
class BrandName: # 클래스 구성
def __init__(self) -> None:
self.trie = None
def return_brand_name_with_jamo(self,text):
# "가르송" -> "ㄱ가ㄹ르ㅅ소송" 으로 반환하는 함수
def return_brand_name_with_ja(self,text):
# "가르송" -> "ㄱㄹㅅ" 으로 반환하는 함수
def __insertBigOneFirst(self, data_list, data):
# Node의 data 리스트에 상품 많은순으로 정렬해 넣기 위한 함수
def returnTrie_ver2(self):
# 한글, 영어(대,소문자), 초성 검색으로 Trie를 구성하는 함수
def searchTrie(self, keyword, resultNum=10):
#키워드를 받으면 해당 키워드에 맞는 단어 목록(기본 10개)을 보여주기
Trie를 구성하는 returnTrie_ver2 를 자세히 살펴보자면
def returnTrie_ver2(self):
df = pd.read_csv("./musinsa_brand_with_eng.csv")
brand_list = df.iterrows()
head = Node(None)
for i, brand in brand_list:
# eng_name insert
eng_name = brand['eng_name']
merchan_count = brand['merchan_count']
current_node = head
for eng in eng_name:
# 대문자 일때 한번
if eng not in current_node.children:
current_node.children[eng] = Node(eng)
insert_index = self.__insertBigOneFirst(current_node.children[eng].data, (eng_name, merchan_count))
current_node.children[eng].data.insert(insert_index, (eng_name, merchan_count))
else:
insert_index = self.__insertBigOneFirst(current_node.children[eng].data, (eng_name, merchan_count))
current_node.children[eng].data.insert(insert_index, (eng_name, merchan_count))
current_node = current_node.children[eng]
current_node = head
for eng in eng_name:
#소문자로 한번
eng = eng.lower()
if eng not in current_node.children:
current_node.children[eng] = Node(eng)
insert_index = self.__insertBigOneFirst(current_node.children[eng].data, (eng_name, merchan_count))
current_node.children[eng].data.insert(insert_index, (eng_name, merchan_count))
else:
insert_index = self.__insertBigOneFirst(current_node.children[eng].data, (eng_name, merchan_count))
current_node.children[eng].data.insert(insert_index, (eng_name, merchan_count))
current_node = current_node.children[eng]
# kor_name insert (가르송티미드 -> ㄱ가ㄹ르ㅅ소송ㅌ티ㅁ미ㄷ드)
kor_name = brand['kor_name']
current_node = head
kor_name_with_jamo = self.return_brand_name_with_jamo(kor_name)
for kor in kor_name_with_jamo:
if kor not in current_node.children:
current_node.children[kor] = Node(kor)
insert_index = self.__insertBigOneFirst(current_node.children[kor].data, (kor_name, merchan_count))
current_node.children[kor].data.insert(insert_index, (kor_name, merchan_count))
else:
if (kor_name, merchan_count) not in current_node.children[kor].data:
insert_index = self.__insertBigOneFirst(current_node.children[kor].data, (kor_name, merchan_count))
current_node.children[kor].data.insert(insert_index, (kor_name, merchan_count))
current_node = current_node.children[kor]
# kor_name insert (가르송티미드 -> ㄱㄹㅅㅌㅁㄷ)
kor_name = brand['kor_name']
current_node = head
kor_name_with_ja = self.return_brand_name_with_ja(kor_name)
for kor in kor_name_with_ja:
if kor not in current_node.children:
current_node.children[kor] = Node(kor)
insert_index = self.__insertBigOneFirst(current_node.children[kor].data, (kor_name, merchan_count))
current_node.children[kor].data.insert(insert_index, (kor_name, merchan_count))
else:
if (kor_name, merchan_count) not in current_node.children[kor].data:
insert_index = self.__insertBigOneFirst(current_node.children[kor].data, (kor_name, merchan_count))
current_node.children[kor].data.insert(insert_index, (kor_name, merchan_count))
current_node = current_node.children[kor]
self.trie = head
return head복잡해 보이지만 크게 4 덩이로 나눌 수 있다.

api의 요청이 왔을 때 Trie에서 찾아 보여주는 searchTrie 를 살펴보자면
def searchTrie(self, keyword, resultNum=10):
# 키워드가 영어인지 한글인지 판단
result = []
current_node = self.trie
for word in keyword:
if not is_hangul_char(word): #키워드가 영어라면
if word in current_node.children:
current_node = current_node.children[word]
else:
result = current_node.data
break
else: #한글이라면?
#자음인지 한글자 인지 확인
if is_jamo(word): # 자음이라면
if word in current_node.children:
current_node = current_node.children[word]
else:
result = current_node.data
break
else:
#자모음이 아니라면 자모 단위로 분해
word_list = self.return_brand_name_with_jamo(word)
for w in word_list:
if w in current_node.children:
current_node = current_node.children[w]
else:
result = current_node.data
break
if len(result) == 0:
result = current_node.data
result = result[-10:][::-1]
return result위처럼 변경 한 뒤, index.html과 api_server.py도 변경해준다.
우선 api_server.py에 아래 코드를 추가해준다.
brandName = BrandName() #인스턴스 생성
head = brandName.returnTrie_ver2() #인스턴스의 Trie 구성 요청
@app.get("/api_v2/")
def return_candidate(q: Union[str, None] = None):
candidate = brandName.searchTrie(q) #구성된 Trie에 키워드 검색
return {"brand" : candidate}index.html의 get_list 함수 부분 수정
function get_list(keyword){
let url = "<http://localhost:8000/api_v2/>" //<-- 변경된 url
$.ajax({
url: url, // 클라이언트가 HTTP 요청을 보낼 서버의 URL 주소
data: { q: keyword }, // HTTP 요청과 함께 서버로 보낼 데이터
method: "GET", // HTTP 요청 메소드(GET, POST 등)
dataType: "json" // 서버에서 보내줄 데이터의 타입
})
// HTTP 요청이 성공하면 요청한 데이터가 done() 메소드로 전달됨.
.done(function(json) {
let dataList = json.brand
$("#brand_list").empty();
for(let brand of dataList) {
let name = brand[0] // <-- 브랜드 이름
let count = brand[1] // <-- 상품수
$("#brand_list").append("<li>"+name+"("+count+")"+"</li>");
}
$("#brand_list").show();
})
}잘 나오는지 확인해보자.
하지만 만들다 보니 한계점이 또 생각났다.
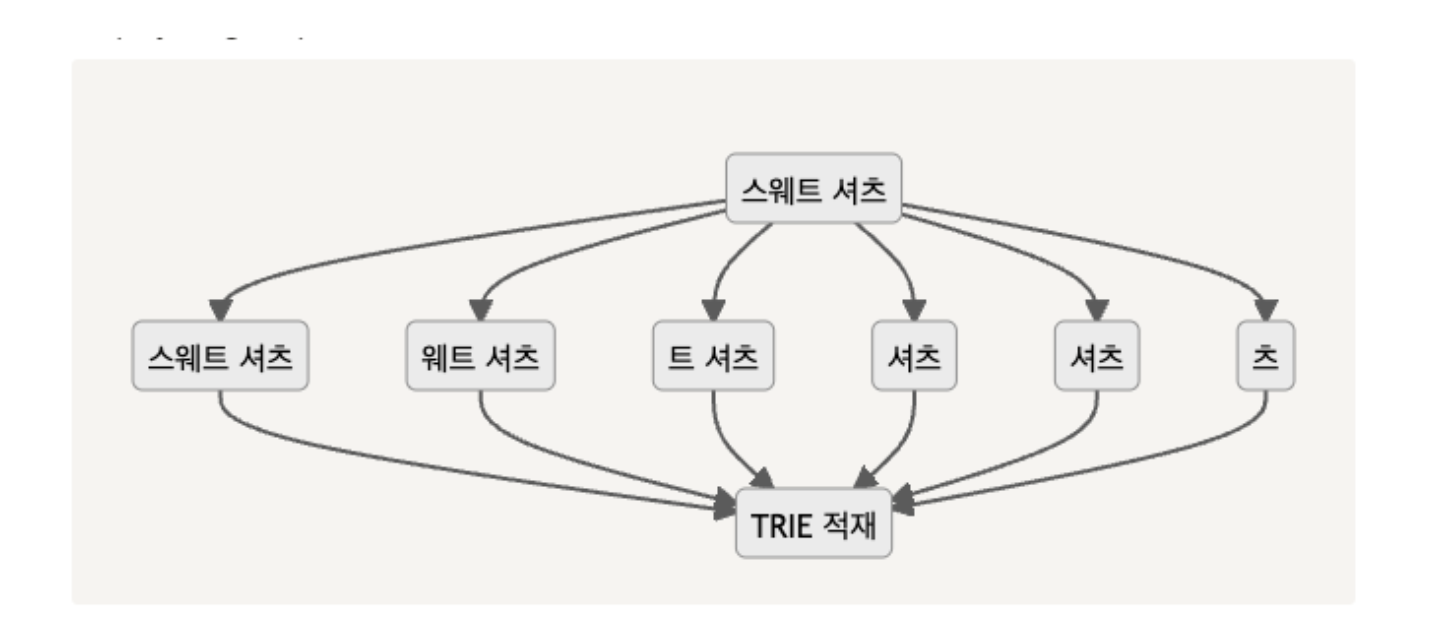
위 29cm 블로그나 무신사 검색의 경우, prefix(접두사) 매칭뿐만 아니라
infix(중위), postfix(접미사) 매칭이 되는 걸 확인할 수 있다.
29cm 블로그에선 그래서 단어를 쪼개서 저장하는데
내 경우엔 브랜드가 카테고리보다 데이터가 많고, (그래 봤자 메모리에 안 올라갈 것 같지 않지만)
저장한 것에 대해 score 계산 로직이 없기에 결과가 별로 일 것 같아 진행하지 않았다.
좀 더 고민해야겠다.
(구글에 쳐보니 suffix Tree라는 키워드가 등장하긴 하는데… 좀 더 알아보고 구성해봐야겠다.)
브랜드 이름 검색어 자동완성 2 (with Suffix Trie)
브랜드 이름 검색어 자동완성 2 (with Suffix Trie)
저번 Trie를 이용한 검색 자동완성의 연장선의 글이다. 브랜드 이름 검색어 자동완성 with Trie 브랜드 이름 검색어 자동완성 with Trie 인터넷을 돌아다니다 글을 하나 보게 됐다. 카테고리 자동완성
hoonzi-text.tistory.com
'text > Python' 카테고리의 다른 글
| 편집거리 알고리즘을 통한 검색어 자동완성 보정 (ft . Levenshtein Distance) (0) | 2022.11.26 |
|---|---|
| 브랜드 이름 검색어 자동완성 2 (with Suffix Trie) (0) | 2022.11.19 |
| 점진적 뉴스 군집화 하기 (incremental news clustering) (1) | 2022.06.06 |
| ㅇㅎ 게시물 수집하기 (fastapi, APScheduler, MySql) (1) | 2022.05.05 |
| 다문서 요약 하기 (multi-document summarization) (0) | 2022.03.01 |




댓글