다문서 요약 하기 (multi-document summarization)
요즘 요약에 관심이 있어서 관련 논문을 찾아 보던중 (취미로)
‘아 이건 나도 구현이 가능할 것 같은데?’ 싶은 논문이 있어서 정리해보려고 한다.
문서 하나에 대해 요약하는 건 블로그에 정리한게 있다. (물론 생성요약이 아니라 추출요약이다.)
요약은 크게 추출 요약 (extractive) 과 생성 요약 (abstractive) 으로 나뉜다.
오늘 해볼 건 추출요약 (extractive) 이다.
참고한 논문은
으로 비슷하게 주제의 기사들의 ‘문장’ 들 간의 밀집도를 바탕으로 중요한 문장을 ‘추출’ 한다.
이 논문에서는 중요도를 크게 3가지로 나누었는데,
representativeness (대표성), diversity (다양성), conciseness(간결성)을 문장의 중요도를 평가하는 지표로 내세웠다.
먼저 각 문장들은 벡터값으로 표현해준다.

뒤 이어 중요한 말이 써있는데 단어를 사용해 문장 벡터를 만들때 여러 방법중 boolean 방법을 사용한게
결과가 제일 좋았어서 그 방법을 이용한다는데...
여기서 boolean 방법이란? 단어가 등장하면 1, 아니면 0을 이용해서 벡터를 구성하는 방법으로
구성하기 쉬운 장점이 있다.

그다음 각 문장들 간의 유사도 (cosine similarity) 를 이용해 유사도를 비교해준다.
(각 문장은 다른 문장간의 유사도를 통해 유사도 벡터를 구성하게 된다...
해당 벡터 공간내 밀집성은 논문에서 제시한 3가지 지표를 통해 구하게 된다. )
해당 유사도를 통해 각 지표 값을 구하게 되는데 식은 다음과 같다.
- representativeness (대표성)

simij 의 경우 i번째 문장과 j번째 문장간의 유사도를 나타낸다.
함수 x의 경우 threshold δ 를 뺀 결과가 0보다 클 경우 1, 아니라면 0을 리턴하는 함수이고,
자기 자신을 제외한(i =/= j) 다른 문장간의 모든 x함수 결과를 합한 값을 평균하면
i번째 문장이 문장 내 가지게 되는 대표성(representativeness) 수치를 구할 수 있다.(call rep(i) )
- diversity (다양성)

다양성 수치를 계산하는 식을 보면 결국 i번째 와 j번째 문장간의 유사도가 클수록
i번째의 다양성 수치는 작아지게끔 만들어져 있다.
비슷한 주제의 문서 내 문장들의 경우, 비슷하거나 동일한 문장들이 다수 포함 되어 있을 수 있는데,
이때 해당 문장이 중요도가 높았을 때 해당 문장과 비슷하거나 동일한 문장만 뽑는다면
결과로 나온 요약이 품질이 높다고 얘기 할 수 없기 때문에 다양성 수치를 구하는 듯 하다.
문제는 위에 적은 듯이 문장 벡터를 boolean 벡터로 표현하는데 있다.
유사도 벡터 표현시 Cosine Similarity 를 사용하는데 boolean 벡터 유사도 계산시 겹치는 term이 하나도 없다면 두 문장간의 유사도는 0이 되고 div(si) 값은 1로 고정이 된다...
- conciseness (간결성)
간결성을 구하기 위해 논문은 문장의 길이를 통해 수치를 계산한다.
el(si) 는 i번째 문장의 unique term의 개수 ⇒ (term set 의 길이라 할수있겠다.)
rl(si) 는 i번째 문장의 실제 term개수
len(si) 는 결국
i번째 문장의 unique term 개수 / 가장 큰 unique term 개수 * log( 제일 긴 문장 길이 / i번째 문장 길이)
라고 표현 될 수 있다.
- DPSC(density peak score) 최종 스코어 계산

위 식은 각 값에 log를 씌워
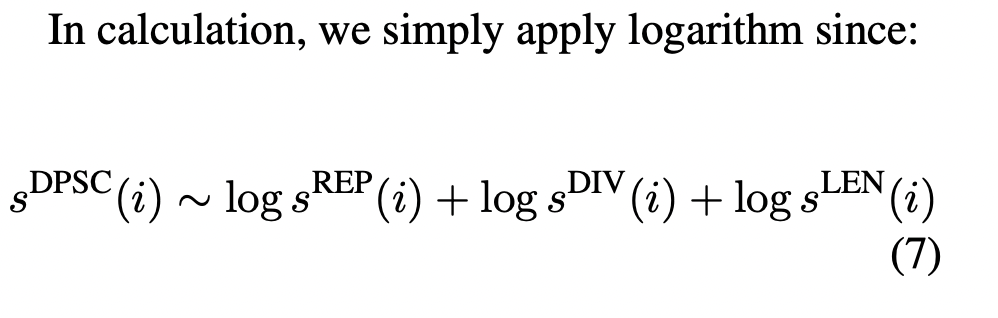
으로 표현할 수 있다. (하지만 위 div(si)의 값이 문제가 된다.)
boolean 벡터로 표현된 문장은 cosine similarity 계산시 결과로 1이 나오게 되고 이 결과에 1을 씌울경우,
log(1) = 0 으로 아무런 영향을 주지 못하게 된다...
(그래서 나는 이번에 테스트 할때 log값을 더하는게 아닌 본래 값을 곱하는것으로 구현했다.)
결론 적으로 문장의 최종 스코어를 계산한 뒤,
스코어가 높은 순으로 나열하면 요약문을 만들 수 있다는게 이 논문의 골자 이다.

구현
해당 논문을 한번 코드로 구현해보자. (jupyter notebook 과 오래되어 수상한 소리가 나는 데스크탑을 이용)
우선 비슷한 주제를 가진 문서를 모아야 한다. (클러스터링 이라고 한다.)
클러스터링도 수도없이 많은 방법이 있지만 우리는 클러스터링이 주된 관심이 아니기 때문에 약식으로 모은다.
‘제목이 비슷하면 내용도 비슷하겠지’ 방법
우선 제목에 나오는 모든 단어(어절 단위)로 vocab을 만들어 준다.
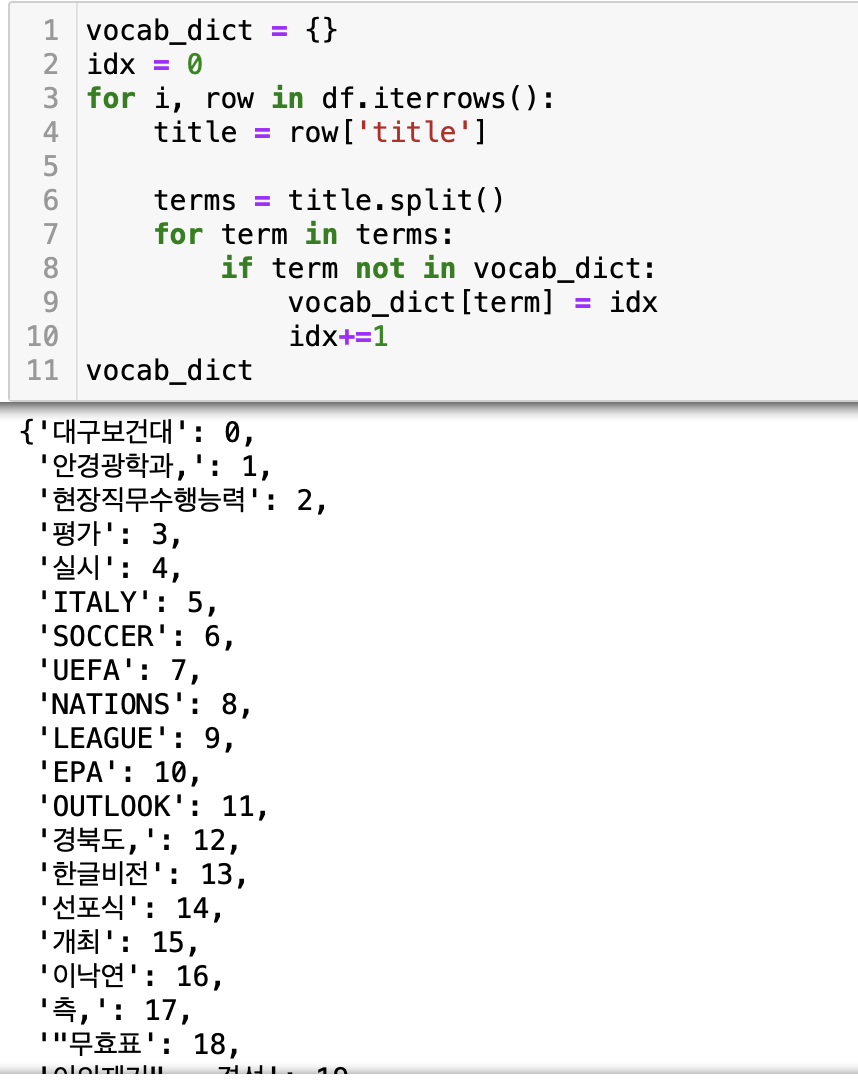
그 다음 해당 vocab으로 제목을 숫자 벡터로 나타내 준다.
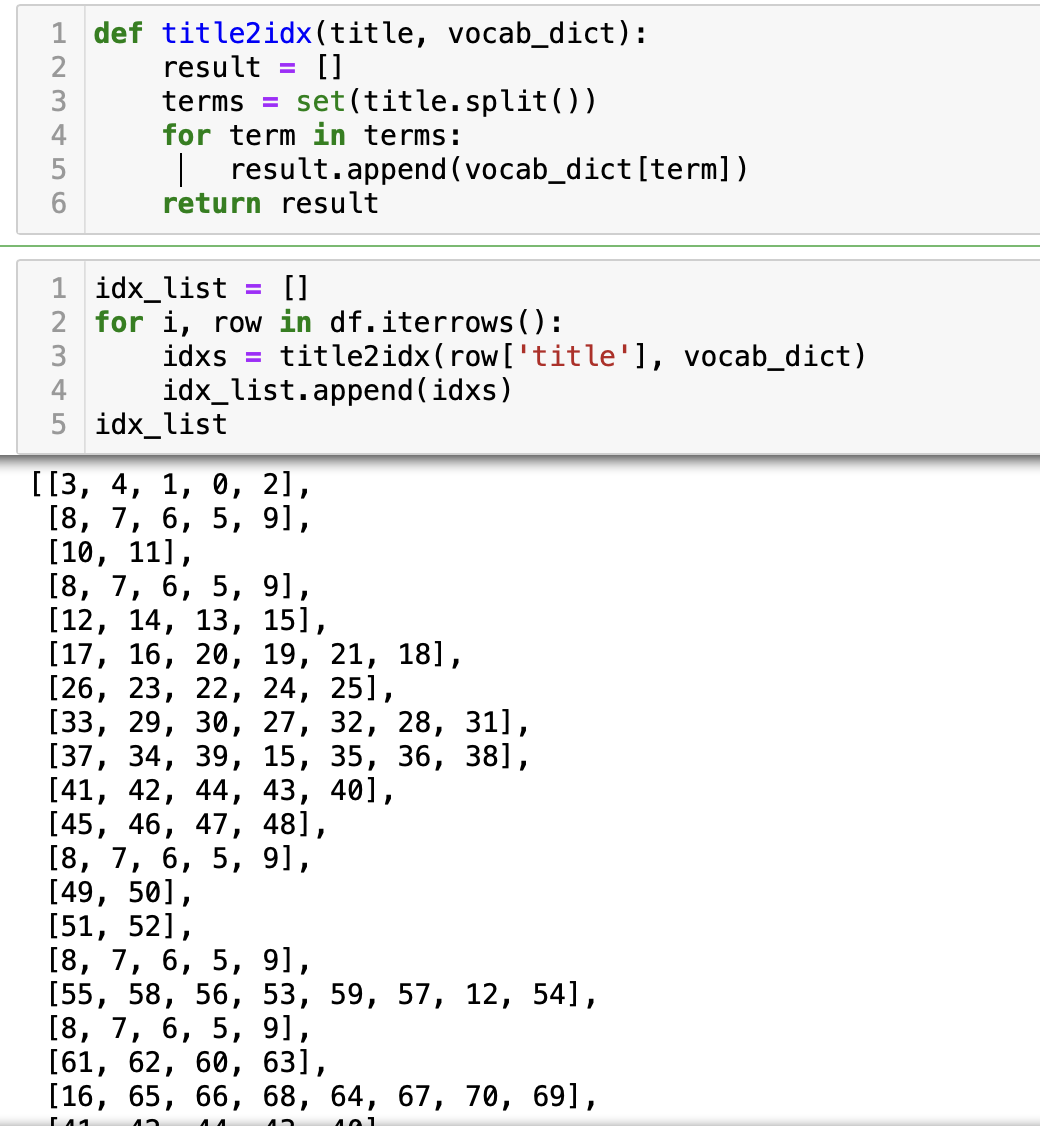
해당 벡터 간의 단순히 겹치는 단어(여기서는 숫자) 가 많을 경우 비슷하다고 여기고 클러스터링 해준다.
sim_dict = {}
already = set()
for i in tqdm(range(len(idx_list))):
if i in already:
continue
for j in range(i+1,len(idx_list)):
stand_len = len(idx_list[i]) if len(idx_list[i]) < len(idx_list[j]) else len(idx_list[j])
inter_len = len(set(idx_list[i]) & set(idx_list[j]))
if (inter_len / stand_len) >= 0.5:
if i in sim_dict:
sim_dict[i].append(j)
else:
sim_dict[i] = [j]
already.add(j)묶은 결과를 보면
클러스터링 된 문서들은 dictionary 형태로 저장했다.
문서 index(stand_idx) : [
제목이 비슷한 문서1_index,
제목이 비슷한 문서2_index,
...
]
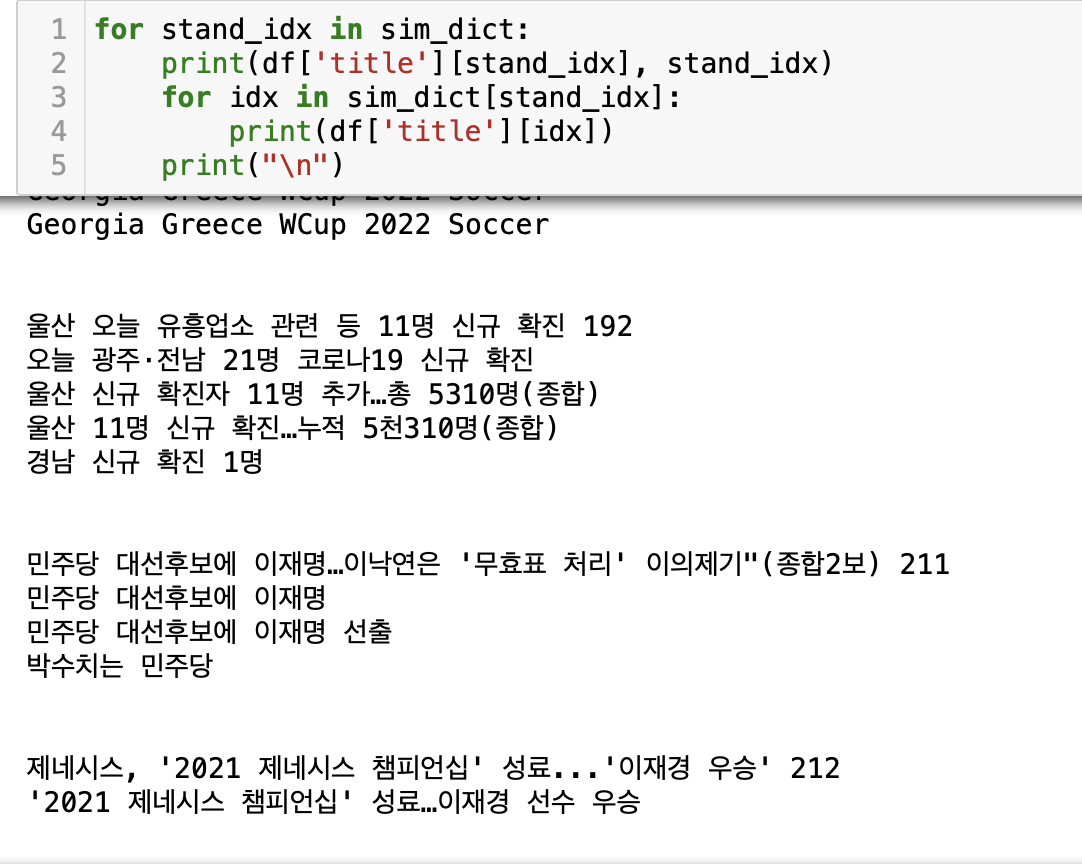
예시 데이터를 확인해보자.
stand_idx = 586 #문서 stand_idx
for idx in sim_dict[stand_idx]: #dictionary 에 저장된 문서들의 제목을 예시로 보기
print(df['title'][idx])
print("*************")
content_list = []
print(df['content'][stand_idx]) # idx를 통해 문서의 기사 내용을 가져오기
content_list.append(df['content'][stand_idx])
print("************")
for idx in sim_dict[stand_idx]:
print(df['content'][idx])
content_list.append(df['content'][idx])
print("************")
비슷한 제목에 비슷한 기사 내용으로 잘 묶여 있는걸 확인 할 수 있다.
(stand_idx 를 통해 비슷한 주제의 기사 를 불러올 수 있음도 확인했다.)
여기에 몇 정제 코드를 통해 기사들 → 문장들로 변형 시킬수 있도록 한다.
def content_refine_temp(content):
content = re.sub("\([^\)]*\)","", content)
content = re.sub("\<[^\]]*\>","", content)
content = re.sub("[\n\t]+",". ", content)
content = re.sub("([^\s]*\s기자)","", content)
content = re.sub("([\w]*@[^\s]*)", "", content)
content = re.sub("\〈[^〉]*\〉","", content)
content = re.sub("(\s=\s)","", content)
content = re.sub("(\s{2,})"," ", content)
return content
for i in range(len(content_list)):
content_list[i] = content_refine_temp(content_list[i])
sentence_list = []
for content in content_list:
for sentence in content.split("다."): #데이터 전체를 확인한게 아니기 때문에 위험하지만
if sentence == "":
continue
else: #'다.' 로 끝나는 경우로 나누고, 없어진 '다.'를 붙혀준다.
sentence_list.append(sentence+"다.")
이제 문장들이 생겼으니 준비물은 전부 준비한 셈이다. (비슷한 주제의 문서의 문장들!)
이제 boolean 벡터로 나타낸 뒤, 벡터간의 유사도(cosine similarity) 를 구해준다.
def cosine_similarity(a,b):
return np.dot(a,b) / (np.linalg.norm(a) * np.linalg.norm(a))
# 문장 내 단어들을 vocab 형식으로 만든다. 단어->idx
vocab_dict = {}
idx = 0
for sentence in sentence_list:
for term in sentence.split():
if term not in vocab_dict:
vocab_dict[term] = idx
idx+=1
# 문장 -> boolean 벡터로 만들어 준다.
terms_list = []
matrix = []
for sentence in sentence_list:
terms = set(sentence.split())
vec = [0.0] * len(vocab_dict)
for term in terms:
vec[vocab_dict[term]] = 1
matrix.append(vec)
terms_list.append(sentence.split())
# i번째 문장과 j번째 문장의 유사도를 구해준다.
sim_matrix = []
for i in tqdm(range(len(matrix))):
sim_vec = []
for j in range(len(matrix)):
score = cosine_similarity(matrix[i], matrix[j])
sim_vec.append(score)
sim_matrix.append(sim_vec)
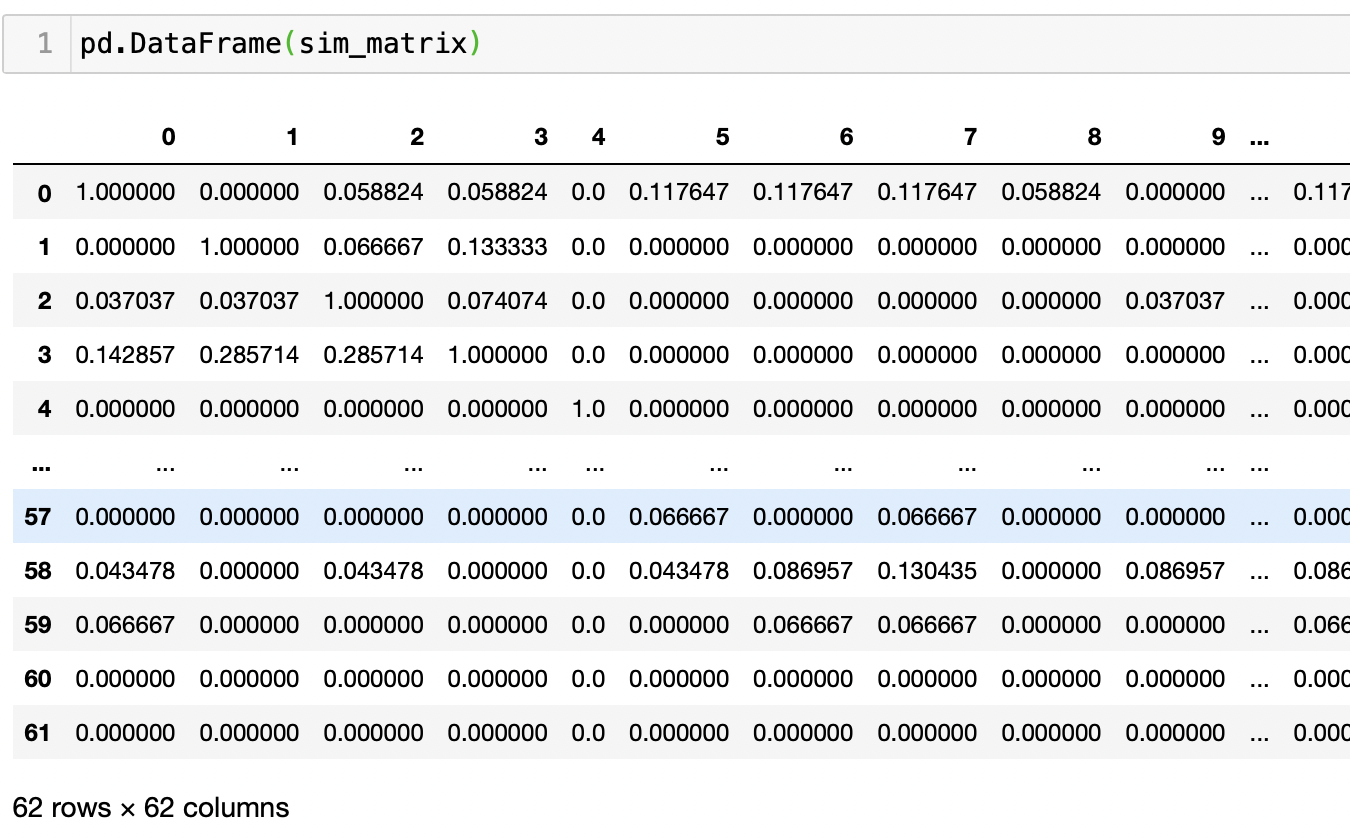
유사도 매트릭스를 보기 쉽게 표현해보자.
0번째 row(행)의 숫자는 0번째 문장과 다른 문장간의 유사도 수치를 나타낸다.
그 다음은 유사도를 이용해 representativeness (대표성), diversity (다양성), conciseness(간결성) 을 계산하는 함수를 구해보자.
- representativeness
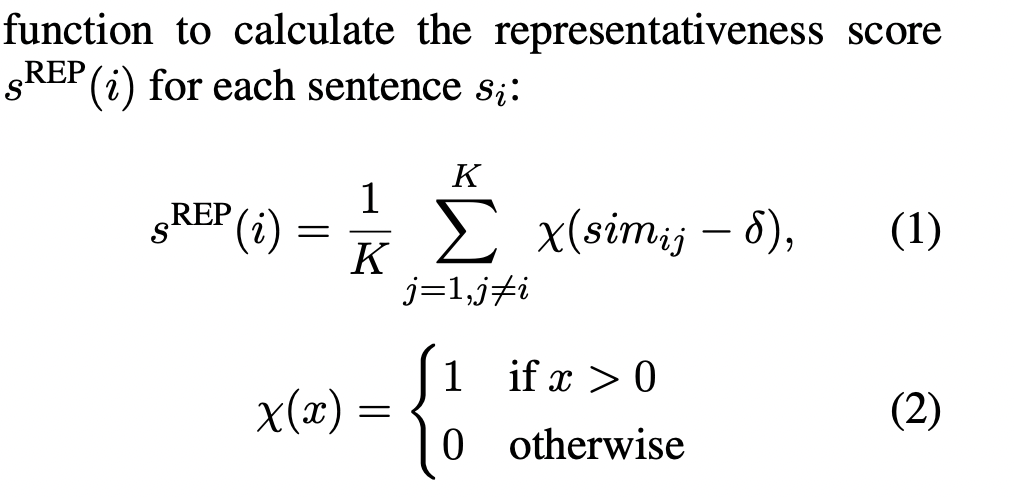
#representive_scoring
def rep_score_return(sim_vec, idx):
count = 0
for i in range(len(sim_vec)):
if i == idx:
continue
else:
if sim_vec[i] > 0:
count += 1
return count / len(sim_vec)논문에 보이는 식과 구현된 함수를 보면 차이점이 있는데 threshold 값을 빼지 않는다는 점이다.
(이유는 딱히 없다. threshold 참고하라고 논문이 있는데 그것까지 읽기엔 귀찮았다.)
그래서 단순히 유사도가 0보다 크다면, 1의 값을 리턴해 합산 하게끔 구현했다.
- diversity

#diversity_scoring
def div_score_return(sim_vec, idx):
min_score = 99
for i, score in enumerate(sim_vec):
if i!=idx and score > 0 and score < min_score:
min_score = score
return min_scoreboolean 벡터 특성상 가장 작은 유사도의 경우 0으로 고정되기 때문에 조건을 하나 추가 했다.
유사도 점수가 0보다 클 경우에만 비교를 수행해 그중 가장 작은 유사도 값을 리턴하게끔 말이다.
- conciseness

#length_scoring
def len_score_return(terms, max_el, max_rl):
if max_rl / len(terms) == 1:
return len(set(terms))/max_el * math.log10(1)
else:
return len(set(terms))/max_el * math.log10(max_rl/len(terms))이전 함수들과 다르게 max_el 과 max_rl을 인자로 받는걸 볼 수 있다.
함수 내 계산시 마다 가장 긴 문장을 골라낼 필요가 없기 때문이다.
문서들내 문장들이 정해지면 가장 긴 문장은 하나로 정해지기 때문에 미리 계산해 인자로 넣어준다.
모인 문장들과 문장 벡터, 점수 계산 함수들로 문장들 간의 점수를 계산 해준다.
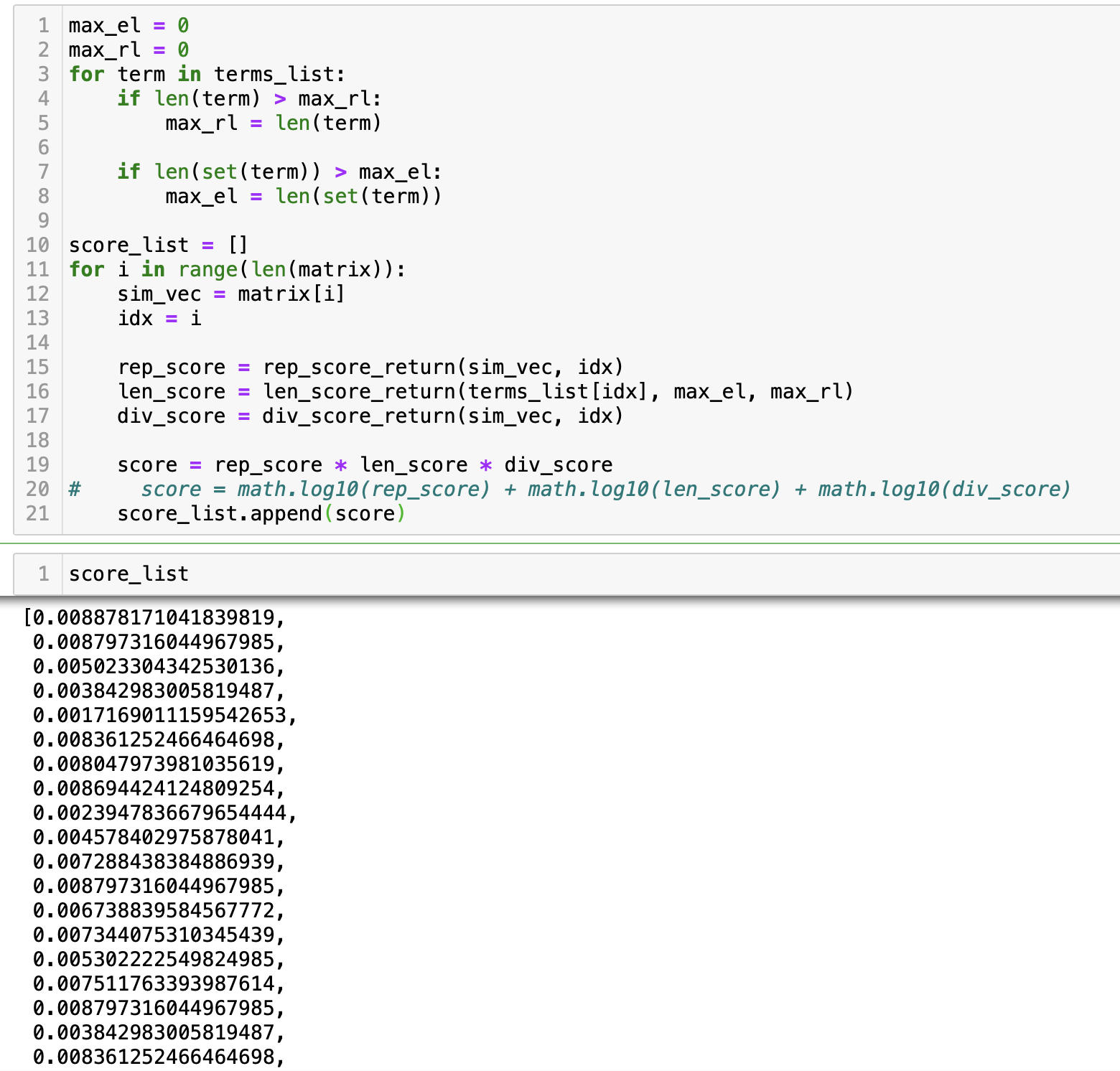
가장 높은 점수를 가진 문장 2개를 뽑아본다.
temp_idx = np.array(score_list).argsort()[::-1][:2]
temp_idx = sorted(temp_idx)
for sen_idx in temp_idx:
print(sen_idx,sentence_list[sen_idx])
print()

요약의 대상이 된 기사의 제목들이다.

잘된 건지 예시를 더 살펴보자.
위에서 구성한 코드와 함수를 하나로 묶어 함수로 구성해준다. (stand_idx를 넣으면 다문서내 문장들로 요약 문을 리턴하게끔)
def multi_document_summary(stand_idx):
content_list = []
content_list.append(df['content'][stand_idx])
for idx in sim_dict[stand_idx]:
content_list.append(df['content'][idx])
for i in range(len(content_list)):
content_list[i] = content_refine_temp(content_list[i])
sentence_list = []
for content in content_list:
for sentence in content.split("다."):
if sentence == "":
continue
else:
sentence_list.append(sentence+"다.")
vocab_dict = {}
idx = 0
for sentence in sentence_list:
for term in sentence.split():
if term not in vocab_dict:
vocab_dict[term] = idx
idx+=1
terms_list = []
matrix = []
for sentence in sentence_list:
terms = set(sentence.split())
vec = [0.0] * len(vocab_dict)
for term in terms:
vec[vocab_dict[term]] = 1
matrix.append(vec)
terms_list.append(sentence.split())
sim_matrix = []
for i in tqdm(range(len(matrix))):
sim_vec = []
for j in range(len(matrix)):
score = cosine_similarity(matrix[i], matrix[j])
sim_vec.append(score)
sim_matrix.append(sim_vec)
max_el = 0
max_rl = 0
for term in terms_list:
if len(term) > max_rl:
max_rl = len(term)
if len(set(term)) > max_el:
max_el = len(set(term))
score_list = []
for i in range(len(matrix)):
sim_vec = matrix[i]
idx = i
rep_score = rep_score_return(sim_vec, idx)
len_score = len_score_return(terms_list[idx], max_el, max_rl)
div_score = div_score_return(sim_vec, idx)
score = rep_score * len_score * div_score
score_list.append(score)
temp_idx = np.array(score_list).argsort()[::-1][:3]
# temp_idx = sorted(temp_idx)
for sen_idx in temp_idx:
print(sen_idx,sentence_list[sen_idx])
해당 함수를 통해 결과를 살펴보자. (달라진건 결과로 보이는 문장의 개수가 2개→3개로 바꿨다.)
예시1

예시2

예시3

위 결과는 내가 눈으로 확인한 후 나름 잘 된걸 가져왔다.
자 이제 잘 안된 걸 확인할 차례다...
예시1

예시2
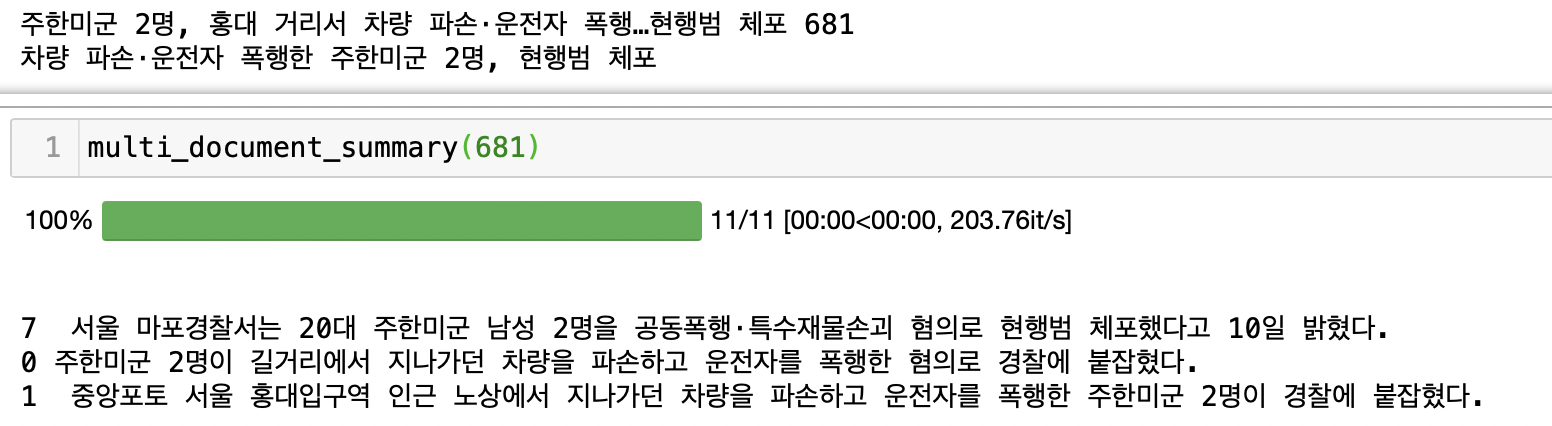
예시 결과를 살펴볼때, 역시 diversity(다양성) 부분의 수치 계산에서 문제가 생긴듯 하다.
(논문에서 하란대로 안해서 그런가?)
그래도 다문서를 요약해 대충 어떤 내용인지 파악할 수 있다는 점에서 유용하게 사용할 수 있을 듯 하다.
(클러스터링이 더 잘된다면 결과가 잘나올까?, 다른 방법에 대해서도 조사가 필요하다!)
코드 전문은 깃허브에 올려두었다.