다음 뉴스 댓글 가져오기
예전에 네이버 댓글을 모았었는데~
네이버 기사 댓글 가져오기
네이버 기사 댓글 가져오기
네이버 기사 댓글 가져오기 들어가기 전 네이버의 robots.txt 에 대해 먼저 숙지하자. 사용 언어 및 모듈 - python 3.7 - request = request 요청을 보내 html 값을 가져오기 ..
hoonzi-text.tistory.com
다음 댓글도 모아서 뭔갈 하면 좋을 거 같아서 이번엔 다음 댓글을 모아봤다.
이번에도 역시 셀레니움은 쓰지 않고 오직 request만 조져서 가져와볼 생각이다.
우선 필요한 모듈들을 불러와 보자.
import pandas as pd # 가져온 데이터를 테이블(rdbs) 형식으로 표기 및 저장
from bs4 import BeautifulSoup # html 을 파싱하기 위한 모듈
import requests # get으로 web 데이터를 가져옴
from tqdm.notebook import tqdm # 진행상황을 jupyter notebook에 표시
from urllib.parse import urlparse, parse_qs # get에 요청을 보낼때 어떤 param이 존재하는지 확인
import json # response값으로 넘어온 json을 파싱
import time # get으로 보내고 time.sleep(1) 실행 (서버에 부담주면 안되니까!)네이버 댓글과 마찬가지로 "더보기" 클릭시 넘기는 값들과 넘어오는 값들을 잘 봐야 한다.
개발자 도구(F12)를 켜서 네트워크 탭을 잘보자.

comment 어쩌구를 잘보니 response 값으로 댓글 json이 넘어온걸 확인 할 수 있다.
해당 request값을 고대로 보내면 response로 댓글을 받을 수 있겠다.

잘보면 /posts 다음에 오는 정체불명의 숫자가 있다. 랜덤 넘버인가? 하고 몇개 다른 숫자들 (456, 16309548, 12345657) 을 넣어봤지만 넘어올때도 안 넘어 올때도 존재했다.
그렇다면 어딘가 저값이 존재(html text 안에 존재) 하거나 어디선가 받아오거나 (특정 api 를 통해 값 받기), 아니면 js내 생성한뒤 보내는 로직이 숨어 있을 수 있다는 생각이 들었다.
- html text안에 존재 할 경우
- BeautifulSoup 모듈을 통해 requests.get으로 받아온 값을 Ctrl+F 해본다 → 결과 존재 x
- js 내 생성되는지 여부 → 확인해봤지만 알수 없음
- 여기서 포기 할 뻔 했다. 함수명이 f,n,o,l 이래서... 하... 일단 후보에서 제외
- 특정 api 가 존재한다 → 빙고

request 로 특정 url (https://comment.daum.net/apis/v1/ui/single/main/) 에 기사 url 마지막 부분을 같이 던져주면

id 값으로 날아온걸 확인 할 수 있었다.
좋아 그럼 저 url에 기사 id를 같이 던져 보자.

자... 권한이 없다는 response를 받는다.
개발자 도구에 request부분을 다시 살펴보자.

저 authorization 부분이 없기 때문에 나타나는 문제였다. (진짜 여기서 포기 할뻔... 저 시리얼 값은 어떻게 조회...)
google 에 검색했다. "댓...그ㄹ...가져...오..기". 검색 결과로 나온 해답
누군가 다음 댓글을 가져오는걸 R 로 구현해놓으셨다.
https://github.com/forkonlp/DNH4/
GitHub - forkonlp/DNH4: 다음 뉴스 수집을 위한 도구
다음 뉴스 수집을 위한 도구. Contribute to forkonlp/DNH4 development by creating an account on GitHub.
github.com
우리가 필요한 부분은 저 authorization 시리얼 값인데

이부분이다. 찾았던 single/main 부분에 들어가는 post_id는 data-client-id를 oauth api에 조회해 알아내야 한다는 것이다.
위 코드를 보면 data-client-id는 html text에 존재하는 것을 알 수 있다.
로직을 세워보자.
- 기사 url로 html 값을 가져온 뒤, data-client-id를 찾는다.
- 찾은 data-client-id로 시리얼(authorization) 값을 얻어온다. (oauth api 조회)
- 찾은 시리얼(authorization) 값으로 post id 를 얻어온다. (single/main api 조회)
- 찾은 post id로 댓글 api에 조회, 값을 반환 받는다.
하나씩 뜯어서 코드로 보자
- 기사 url 로 html 값을 가져온 뒤, data-client-id를 찾는다.
#access_token_id 반환
org = #기사 url ex. https://news.v.daum.net/v/20211125234942863
article_id = org.split("/")[-1] # ex.20211125234942863
req = requests.get(org)
soup = BeautifulSoup(req.content)
data_client_id = soup.find('div',{'class':'alex-area'}).get('data-client-id')2. 찾은 data-client-id로 시리얼(authorization) 값을 얻어온다. (oauth api 조회)
header = {
'authority' : 'comment.daum.net',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
'accept' : "*/*",
'accept-encoding' : 'gzip, deflate, br',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'referer' : "",
}
# authorization 값 반환
header['referer'] = org # referer 값을 꼭 추가해주자
token_url = "https://alex.daum.net/oauth/token?grant_type=alex_credentials&client_id={}".format(data_client_id)
req = requests.get(token_url, headers=header)
access_token = json.loads(req.content)['access_token']
authorization = 'Bearer '+access_token3. 찾은 시리얼(authorization) 값으로 post id 를 얻어온다. (single/main api 조회)
# article - comment 연결 짓는 key값 반환
header['authorization'] = authorization # authorization 값을 꼭 추가
post_url = """https://comment.daum.net/apis/v1/ui/single/main/@{}""".format(article_id)
req = requests.get(post_url, headers = header)
soup = BeautifulSoup(req.content,'html.parser')
post_id = json.loads(soup.text)['post']['id'] # 드디어 드러나는 post id 의 값4. 찾은 post id로 댓글 api에 조회, 값을 반환 받는다.
# comment 조회
offset = 0
request_url = """
https://comment.daum.net/apis/v1/posts/{}/comments?parentId=0&offset={}&limit=100&sort=RECOMMEND&isInitial=false&hasNext=true
""".format(post_id, offset)
req = requests.get(request_url, headers=header)
soup = BeautifulSoup(req.content,'html.parser')
temp_json_list = json.loads(soup.text)
댓글 예시
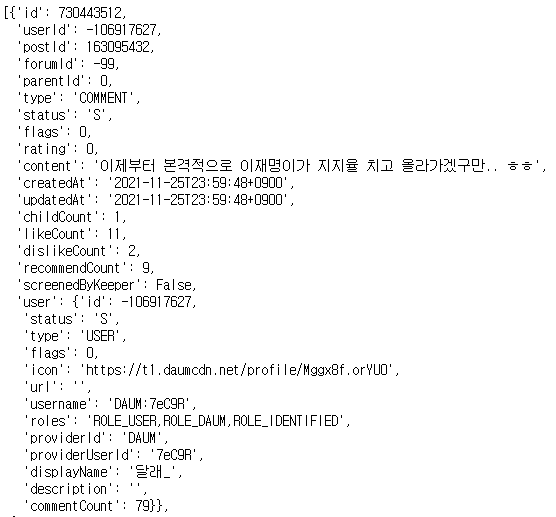
offset 을 url에 설정해 댓글의 개수가 limit보다 많을 경우 다음 댓글을 가져온다
(ex. 0, 100 → 1, 100 → 2, 100 식으로...)
내 경우엔 (2021-11-25 일자 / 정치 속보 기사들) url 을 pandas dataFrame 에 미리 저장해놨고, 해당 url을 반복해서 돌면서 댓글 데이터를 가져왔다. 해당 부분에 대한 전체 코드를 첨부한다.
comment_list = []
for index, row in tqdm(df.iterrows(), total=len(df)):
header = {
'authority' : 'comment.daum.net',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
'accept' : "*/*",
'accept-encoding' : 'gzip, deflate, br',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'referer' : "",
}
#access_token_id 반환
org = row['url']
article_id = org.split("/")[-1]
req = requests.get(org)
soup = BeautifulSoup(req.content)
data_client_id = soup.find('div',{'class':'alex-area'}).get('data-client-id')
# authorization 값 반환
header['referer'] = org
token_url = "https://alex.daum.net/oauth/token?grant_type=alex_credentials&client_id={}".format(data_client_id)
req = requests.get(token_url, headers=header)
access_token = json.loads(req.content)['access_token']
authorization = 'Bearer '+access_token
# article - comment 연결 짓는 key값 반환
header['authorization'] = authorization
post_url = """https://comment.daum.net/apis/v1/ui/single/main/@{}""".format(article_id)
req = requests.get(post_url, headers = header)
soup = BeautifulSoup(req.content,'html.parser')
post_id = json.loads(soup.text)['post']['id']
count = len(comment_list)
# comment 조회
offset = 0
while True:
request_url = """
https://comment.daum.net/apis/v1/posts/{}/comments?parentId=0&offset={}&limit=100&sort=RECOMMEND&isInitial=false&hasNext=true
""".format(post_id, offset)
req = requests.get(request_url, headers=header)
soup = BeautifulSoup(req.content,'html.parser')
temp_json_list = json.loads(soup.text)
for temp_json in temp_json_list:
temp_json['org_url'] = org
comment_list.extend(temp_json_list)
if len(temp_json_list) < 100:
break
else:
offset += 100
time.sleep(1)
print(article_id, len(comment_list) - count)실행예시 화면
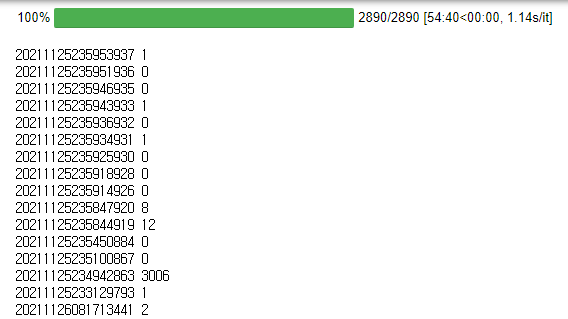
각 기사 마다 댓글들을 잘 가져오는걸 볼 수 있다.
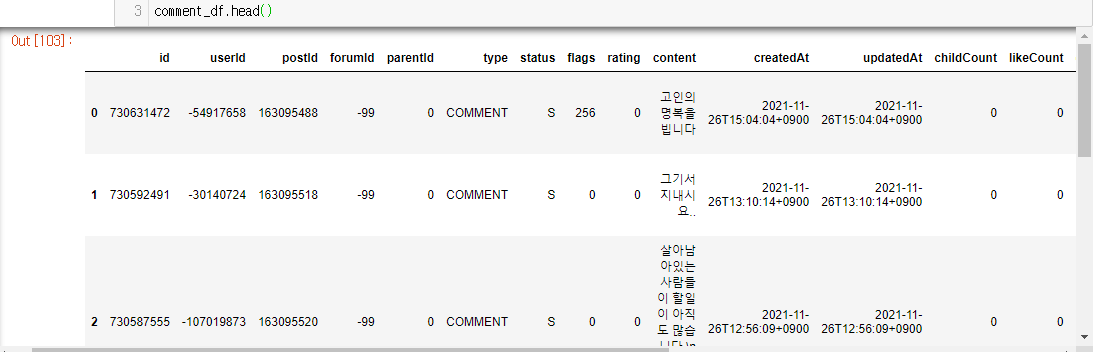
내 경우엔 {댓글 dataframe} 과 {기사 dataframe} 을 나중에 연결하기 편하게(일종의 foreign key)
{댓글 dataframe} 에 기사 url 값을 추가했다.
나중에는 스케줄 작업을 통해 한번 가져온 기사 댓글에 대해
추가되는 값이 존재할 경우 해당 댓글을 가져오는 로직으로 발전시키고 싶다.
그럼 이만!