뉴스 문서 군집화 하기.ver2 ( document clustering using Minhash & LSH)
두 문서의 유사도는 문서에 나타난 요소들 (ex. 음절, 어절, 형태소) 을 집합 형태로 만들어 집합간의 비교로 치환해 비교할 수 있다.
문서1 = "나는 밥을 먹었다. 나는 학교에 갔다."
문서2 = "나는 밥을 먹었고, 학교에 갔다."
두 문서가 존재 할때 두 문서를 어절 단위(띄어쓰기로 나눠서) 집합으로 변경시켜보면
문서1_집합 = { '나는', '밥을', '먹었다.', '학교에', '갔다.' }
문서2_집합 = { '나는', '밥을', '먹었고,', '학교에', 갔다.' }
이때 두 문서의 유사성을 비교할때 여러 방법들이 존재하지만 이번 글에서는 자카드 유사도(Jaccard similarity) 라는 방법을 이용한다.
자카드 유사도 ⇒
https://ko.wikipedia.org/wiki/자카드_지수
자카드 지수 - 위키백과, 우리 모두의 백과사전
자카드 지수(Jaccard index)는 두 집합 사이의 유사도를 측정하는 방법 중 하나이다. 자카드 계수(Jaccard coefficient) 또는 자카드 유사도(Jaccard similarity)라고도 한다. 자카드 지수는 0과 1 사이의 값을 가
ko.wikipedia.org

위키피디아의 식을 글로 풀어보자면
두문서의 유사도 = 두문서의 교집합 요소 갯수 / 두문서의 합집합 요소 갯수
으로 풀어서 쓸수 있고, 위 문서1과 문서2의 유사도는
두문서의 교집합 = {'나는', '밥을', '학교에', '갔다.'} (4개)
두문서의 합집합 = {'나는', '밥을', '먹었고,', '먹었다.', '학교에', '갔다.'} (6개)
4/6 = 2/3 = 약 0.66이라는 수치를 얻을 수 있다.
좀더 단순화 해보자
문서에 등장하는 요소(token t)에 대해서 t 가 문서에 나오면 1, 나오지 않으면 0 으로 나타내면
| token | document1 | document2 |
| 나는 | 1 | 1 |
| 밥을 | 1 | 1 |
| 먹었고, | 0 | 1 |
| 먹었다. | 1 | 0 |
| 학교에 | 1 | 1 |
| 갔다. | 1 | 1 |
문서1 = [1,1,0,1,1,1]
문서2 = [1,1,1,0,1,1]
로 벡터값으로 치환가능하다.
만약 문서의 수가 늘어나고, 그에 따라 기존 문서에 없던 요소들이 등장할수록 문서1 벡터에 [0]으로 채워지는 값은 늘어날 것이다.
벡터를 놓고 보자면 벡터의 차원 수가 증가한다고 얘기할 수 있다.
예시와 같이 단문의 경우, 나오는 요소의 개수가 작고 전체 문서가 작으니 컴퓨터가 계산하기에 어렵지 않지만 뉴스나 책과 같이 전체 글이 길고, 문서의 개수가 많다면 문서와 문서간의 유사도 비교를 하기 위해 오래걸릴 것이다.
정리 하자면 시간이 오래걸리는(컴퓨팅 파워가 많이 필요한) 이유는 두가지라고 정리 할수 있다.
- 문서 벡터의 차원수가 크다.
- 비교해야될 문서의 개수가 많다.
위 두가지를 해결하는 방법을 밑에서 알아보자
hash는 컴퓨터 공학 전공자라면 다들 아는 알고리즘의 한종류이다.

hash table의 경우 큰 파일의 레코드를 그보다 작은 바구니(bucket)에 "고루 담기게끔" 해서
다음에 특정 레코드를 찾을때 레코드 전체를 찾는 것이 아닌
해당 자료가 들어있는 bucket을 뒤지는 방식으로 탐색속도를 줄인다.
(ex. 책제목을 찾는다고 생각해보자. 도서관에서 'a'로 시작하는 책인 경우 'a' section만 뒤지면 된다.)
그렇다면 비슷한 문서의 경우 같은 bucket에 담기면서 벡터의 차원수를 줄이는 방법이 있을까?
이때, min-hash라는 방법이 등장한다.
Minhash
https://en.wikipedia.org/wiki/MinHash
MinHash - Wikipedia
In computer science and data mining, MinHash (or the min-wise independent permutations locality sensitive hashing scheme) is a technique for quickly estimating how similar two sets are. The scheme was invented by Andrei Broder (1997),[1] and initially use
en.wikipedia.org
영어 원문으로 되어 있지만 쉽게 말하자면 두 문서간의 자카드 유사도를 비슷하게 보존하면서,
벡터의 차원수를 줄여주는 방법이라고 생각하면 될 것이다.
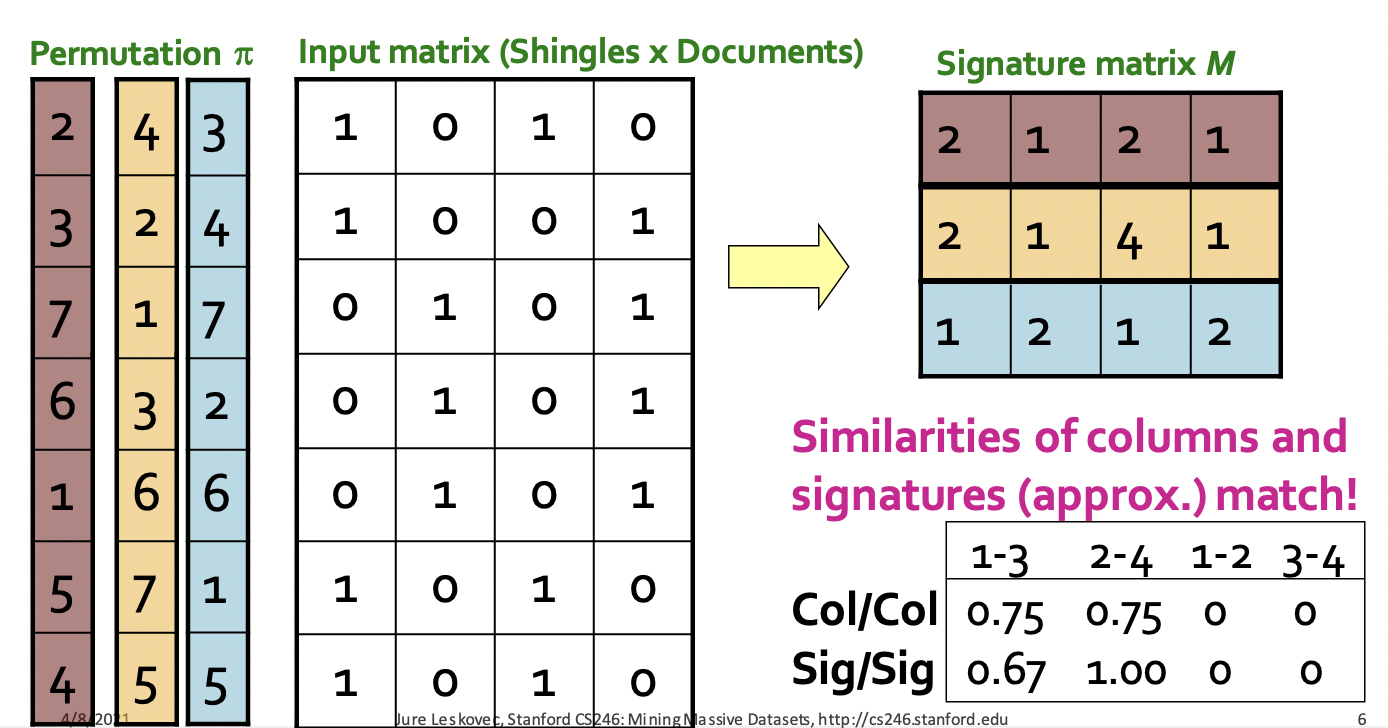
위 그림에서 input matrix부터 살펴보자. 위 문서 벡터행렬처럼
row = 요소(token) / column = 문서 이고
input_matrix 왼쪽으로 보이는 건 row의 index를 permutation 한 값이다.
문서 행렬에서 row 값이 같으면 같은 permutation 값을 가진다.
permutation 1번 (자주색?) 기준으로 row가 1인 값을 보자
문서_1 = {2,3,4,5} // row값이 1일때 permutation 값
문서_2 = {1,6,7}
문서_3 = {2,4,5}
문서_4 = {1,3,6,7}
hash function을 통해 문서1 과 문서3, 문서2와 문서4가 비슷한걸 벌써 확인할 수 있다
(hash 안해도 확인할수있는데?)
이때 min 의 의미가 나타난다.
문서_1 = min({2,3,4,5}) = 2
문서_2 = min({1,6,7}) = 1
문서_3 = min({2,4,5}) = 2
문서_4 = min({1,3,6,7}) = 1
문서 1개당 요소의 수가 10개 (=10차원) 이던 문서가 hash function 이후 1개의 값으로 줄여졌다.
이후 왼쪽에 남은 permutation 을 마저 진행하면 10차원 ⇒ 3차원으로 줄여진걸 확인할 수 있다.
줄여진 차원수 밑에 나온 값은 원래 input_matrix 의 자카드 유사도와 3차원으로 차원축소가 된 matrix의 자카드 유사도를 비교한 값으로 원래 값과 근사하게 나온다는 걸 확인시켜준 표이다.
LSH
lsh의 경우, minhash를 통해 나온 matrix를 일정길이로 구간을 나눠 해당 구간별로 동일한 부분이 있는지 여부를 체크해 비교해야될 문서 대상군을 좁히는 방법이다.
우리는 minhash를 통해 변환된 matrix m 를 r 개의 row를 가진 band로 나눈다. 그림으로 보자.

분홍색으로 그려진 하나의 띠는 하나의 문서 벡터를 나타낸다.
b 개의 band로 나눠서 각 구간의 row 개수를 r이라고 할때
문서 벡터 = b*r 이라고 나타낼수 있다.
(만약 문서 벡터 m이 20차원이라고 할때 5개의 band로 나누면 하나의 band에는 row가 4개 들어있다.
⇒ 20 = 5(band) * 4(r) )
그리고 겹치는 band의 개수가 많을 수록 비슷한 문서라고 특정할수 있다. 만약 하나도 겹치지 않는다면
우리는 그문서는 유사도 비교 후보군(candidate) 에서 제외해도 될 것이다.

lsh는 threshold 값을 설정한다. 위 설명에서는 "비교 band의 row값이 동일할때" 라고 얘기했지만 정확히 말하자면 비교하는 band의 row 간 유사도 값이 사용자가 설정한 값(threshold) 이상 일때 같은 bucket에 넣어 candidate pair를 만드는 것이다.
좀 더 자세한 설명은 해당 링크를 참조하자.
https://towardsdatascience.com/understanding-locality-sensitive-hashing-49f6d1f6134
Locality Sensitive Hashing
An effective way of reducing the dimensionality of your data
towardsdatascience.com
(여기가 제일 자세하게 적어놓긴 했다...)
실습
실습을 통해 결과를 살펴보자.
# 사용한 모듈 import pandas as pd # 기사 데이터를 데이터프레임 정리 import re # 전처리 모듈 from tqdm.notebook import tqdm # 진행상황 가시화 from datasketch import MinHash, MinHashLSH #minhash, lsh 모듈!
데이터는 2021-07-23 네이버 뉴스에서 수집한 기사를 사용했다. (뒤에선 데이터를 바꾼다)
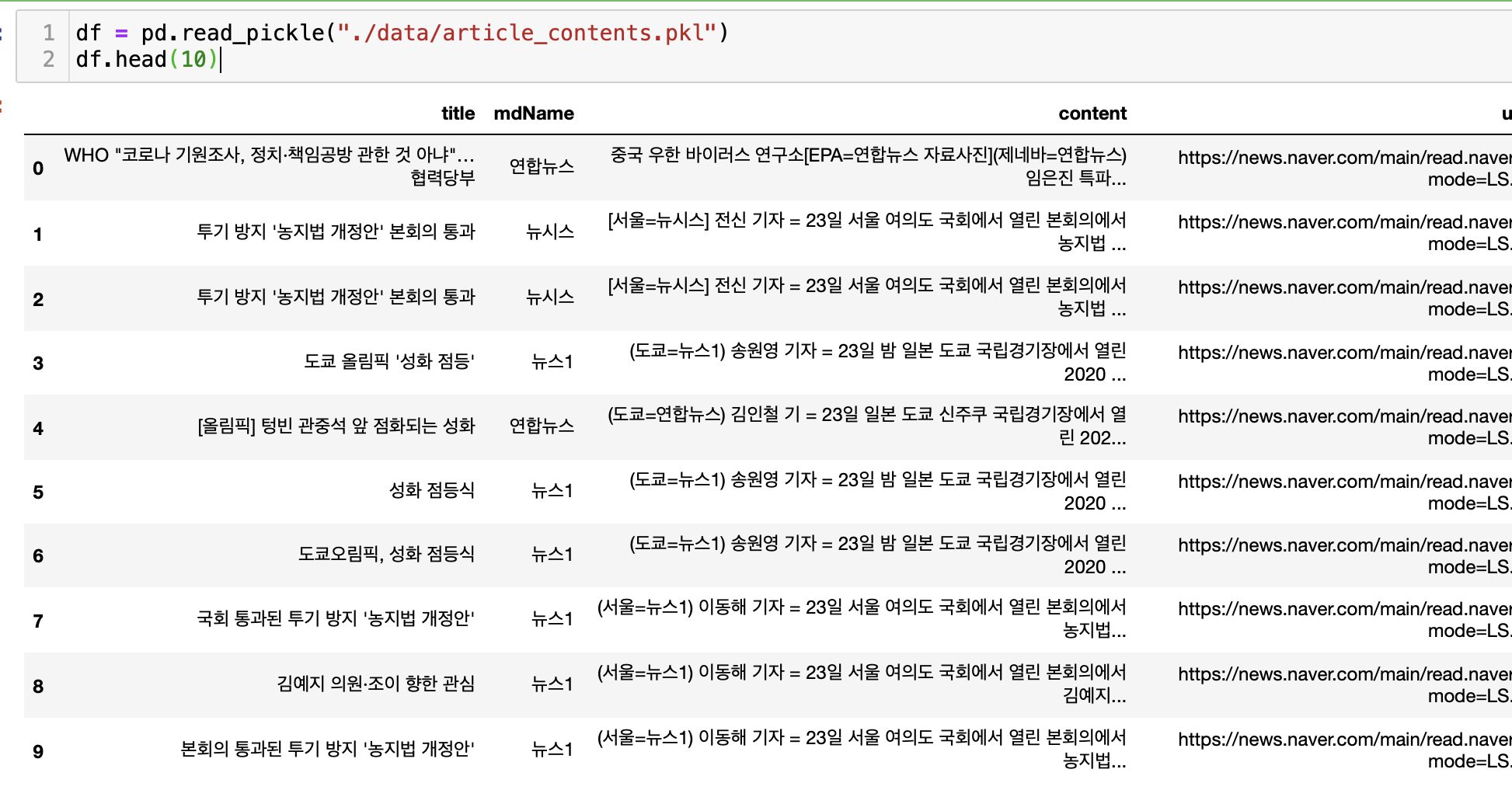
이제 약간의 전처리를 해준다.
#전처리 함수 def contents_preprocessing(contents): # 괄호와 괄호안 문자열을 지우는 regex braket = r'\[[^\]]*\]|\([^\)]*\)|\{[^\}]*\}' contents_sample = re.sub(braket, "", contents) # "=" 기호 이전 혹은 이후 문자열을 지우는 함수(ex. "전신 기자 =" 같은 내용과 관련없는 문자열) index = 0 if "=" in contents_sample: index = contents_sample.index("=") if len(contents_sample[:index]) < len(contents_sample[index+1:]): contents_sample = contents_sample[index+1:] else: contents_sample = contents_sample[:index] # 이메일 문자열 지우기 pattern = r'([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)' contents_sample = re.sub(pattern, "", contents_sample) # 줄바꿈, tab 공백 지우기 pattern = r'\n*|\t*|\r\n*' contents_sample = re.sub(pattern, "", contents_sample) # 영어, 한글, 숫자 이외 문자들 제거 pattern = r'[^a-zA-Z가-힣0-9]' contents_sample = re.sub(pattern, "", contents_sample) contents_sample = contents_sample.strip() contents_sample = contents_sample.replace(" "," ") return contents_sample
저 함수에서 (영어, 한글, 숫자 이외의 문자들 제거) 하는 regex의 경우 나중에 추가되었다.
이번 실습에서는 10-shingles 로 만들거라 띄어쓰기조차 제거했다.

이제 각 문서 요소(10-shingles token)을 minhash 방법을 통해 벡터로 치환해보자.
나는 datasketch 라이브러리를 이용했다.
http://ekzhu.com/datasketch/index.html
datasketch: Big Data Looks Small — datasketch 1.0.0 documentation
datasketch: Big Data Looks Small datasketch gives you probabilistic data structures that can process and search very large amount of data super fast, with little loss of accuracy. This package contains the following data sketches: The following indexes for
ekzhu.com
해당 페이지의 MinHash lsh를 보면 document와 간단한 example을 참고할 수 있다.
위 페이지의 example을 보면
from datasketch import MinHash, MinHashLSH set1 = set(['minhash', 'is', 'a', 'probabilistic', 'data', 'structure', 'for', 'estimating', 'the', 'similarity', 'between', 'datasets']) set2 = set(['minhash', 'is', 'a', 'probability', 'data', 'structure', 'for', 'estimating', 'the', 'similarity', 'between', 'documents']) set3 = set(['minhash', 'is', 'probability', 'data', 'structure', 'for', 'estimating', 'the', 'similarity', 'between', 'documents']) # document shingles set을 minhash vector로 만드는 과정이다. m1 = MinHash(num_perm=128) # permutation의 숫자는 128개 = vector의 요소수 128개 m2 = MinHash(num_perm=128) m3 = MinHash(num_perm=128) for d in set1: m1.update(d.encode('utf8')) for d in set2: m2.update(d.encode('utf8')) for d in set3: m3.update(d.encode('utf8'))
각 문서를 minHash 클래스를 통해 128개의 값을 가진 벡터로 치환한다.

그다음 각 벡터를 lsh에 넣고 m1 문서와 자카드 유사도 수치상으로 비슷한 문서를 result값으로 저장한다.
# Create LSH index lsh = MinHashLSH(threshold=0.5, num_perm=128) lsh.insert("m2", m2) lsh.insert("m3", m3) result = lsh.query(m1) print("Approximate neighbours with Jaccard similarity > 0.5", result)설명이 부족해보여 해당 모듈 도큐먼트에서 설명을 긁어온다;;

실제로 해보자
기사 dataFrame을 통해 minHash vector를 구성하고,
해당 vector를 lsh에 넣고, 각 문서별로 비슷한 문서가 무엇인지 result값으로 도출하면 된다.
lsh = MinHashLSH(threshold=0.9, num_perm=128) #lsh 정의 mh_list = [] #각 문서 벡터가 저장될 리스트 정의 for i, row in tqdm(df.iterrows(), total = len(df)): content_sample = row['content'] # 10Shingle을 만들 기사 token_set = set() #자카드 유사도 이기에 리스트가 아닌 set으로 구성 for index in range(0, len(content_sample), 10): token = content_sample[index : index+10] token_set.add(token) mh = MinHash(num_perm = 128) # 벡터 만들기 for token in token_set: mh.update(token.encode('utf8')) mh_list.append(mh) # 만들어진 벡터를 벡터 리스트에 저장 lsh.insert(i,mh) # (i번째 문서를 lsh에 넣기)
mh_list (minhash vector instance) 를 루프 돌면서 각 문서와 비슷한 문서의 index를 반환 받는다.

sim_list = [] # 각 문서별 해당 문서와 비슷한 문서가 for i, mh in enumerate(mh_list): result = lsh.query(mh) sim_list.append(result) df['sim_document'] = sim_list # 문서별 비슷한 문서 index를 dataframe에 추가 시켜주자 df.head()
중간에 2번행의 경우 "도쿄 올림픽 '성화 점등' 기사와 비슷한 문서로
[2(자기자신),4,5,9,10,11] 이 도출된 걸 볼수 있다. 실제로 그런지 한번 봐보자

오 생각보다 잘나오는걸 눈으로 확인할 수 있다.
기사 콘텐츠 까지 일일히 확인하는건 너무 오래 걸리니 실제로 묶인 기사들간의 공통적인 주제로 묶인지 제목만 보면서 판단해보자.
cluster_list = [] # 결과값을 저장하는 리스트 visited = set() # 한번 다른 기사와 유사하다고 등장한 기사의 경우 루프에서 제거 하기 위해 for index, row in tqdm(df.iterrows(), total=len(df)): if index in visited: # 다른 기사와 묶였다고 등장한 경우 continue # 건너뛰기 else: # {title=제목, sim_document=해당기사와 비슷하다고 묶인 기사리스트} sim_dict = dict() sim_dict["title"] = row['title'] title_list = [] sim_documents = row['sim_document'] #minHash-lsh의 결과 sim_documents = sorted(sim_documents) for s_index in sim_documents: if s_index == index: # 비슷한 문서의 결과로 자기 자신이라면 제외 visited.add(s_index) continue else: s_title = df['title'][s_index] # 비슷한 문서의 제목을 가져오기 title_list.append(s_title) # 제목 리스트에 저장 visited.add(s_index) if len(title_list) == 0: continue # 비슷한 문서가 없다면 넘어가기 sim_dict["sim_document"] = title_list cluster_list.append(sim_dict) #해당 결과 dictionary를 리스트에 하나씩 저장
결과를 보면 두가지 생각이 든다.
- 앞서 봤듯이 '성화 점등' 이라는 주제에 비슷한 기사들이 묶인것을 볼수있다.
- '투기 방지' 주제라는 같은 주제임에도 묶이지 않은 기사들이 보인다.
저번 dbscan을 이용해 클러스터링때와 마찬가지로 동일 주제임에도 다른 클러스터로 묶인 경우가 나타났고,
마지막에 써놓은 개선점중 하나를 이용해 보기로 했다.

클러스터는 title / sim_document_title_list 로 나뉘는데 이걸 title / content 로 바꿔 생각해보자
그럼 다시 문서 비교로 바꿔 생각할 수 있게 된다.

# sim_document 대신 sim_index로 변경 / title_list를 sim_document로 변경 cluster_list = [] visited = set() for index, row in tqdm(df.iterrows(), total=len(df)): if index in visited: continue else: sim_dict = dict() sim_dict["title"] = row['title'] title_list = [] sim_documents = row['sim_document'] sim_dict['sim_index'] = sim_documents sim_documents = sorted(sim_documents) for s_index in sim_documents: if s_index == index: visited.add(s_index) continue else: s_title = df['title'][s_index] title_list.append(s_title) visited.add(s_index) if len(title_list) == 0: continue sim_dict["sim_document"] = title_list cluster_list.append(sim_dict)title_list를 sim_document로 index(dataframe내 문서 위치)를 sim_index로 다르게 저장한다.
# title_list => content로 변환하는 작업 및 해당 결과를 다시 dataframe으로 보기좋게 만들기! data = [] for info in cluster_list: title = info['title'] sim_index = info['sim_index'] sim_document = info['sim_document'] content = "" #title + sim_document_title concat for sim_title in sim_document: content += sim_title+" " content += title pattern = r'[^ a-zA-Z가-힣0-9]' content = re.sub(pattern,"",content) temp_list = [title, content, sim_index] data.append(temp_list) filter_df = pd.DataFrame(data, columns=['title','content','sim_index']) filter_df.head()
다시 title / content 의 형태로 바뀐걸 확인 할수 있다. 문서가 준비 되었으니 다시금 MinHash lsh 의 방법을 사용하는데,
위 10-shingles와 다르게 띄어쓰기 단위로 나눴다.
제목의 경우, 보통 기사의 핵심키워드를 담아 쓴다고 가정했기에 키워드의 의미가 없어지는걸 방지하기 위해서다.
lsh = MinHashLSH(threshold=0.8, num_perm=10) mh_list = [] for i, row in tqdm(filter_df.iterrows(), total = len(filter_df)): content = row['content'] token_set = set(content.split()) mh = MinHash(num_perm = 10) for token in token_set: mh.update(token.encode('utf8')) mh_list.append(mh) lsh.insert(i,mh) sim_list = [] for i, mh in enumerate(mh_list): result = lsh.query(mh) sim_list.append(result) filter_df['sim_cluster'] = sim_list filter_df.head()
스크린샷에 보이는 것과 같이 sim_cluster의 경우 cluster끼리 비슷한 경우 해당 dataFrame index를 리스트로 저장했다.
주목해야 하는건 0번째 문서의 sim_cluster이다.
아까 묶이지 못했던 '투기 방지' 주제의 클러스터 2개가 묶여있는걸 확인할 수 있다.
결과를 json 형태로 뽑아서 확인해보자.

하지만 여전히 묶이지 못한 결과도 존재했다.

해결 방안을 생각해보다 문득 lsh의 threshold 값이 너무 높았다는 생각이 들었다.
처음 클러스터링을 할때야 확실히 비슷한 것끼리 묶여야 하니 기준값을 높여야 하지만
제목으로 만든 content의 경우 기사에 비해 문장 구조가 짧기 때문에
비슷한 주제더라도 겹치는 단어가 적을 수 있다.
또한, 한번 묶을때 title_list가 늘어나는 구조라면 묶이지 않을 때까지
클러스터링을 반복하면 좀 더 정확한 결과를 도출할 수 있지 않을까? 하는 생각이 들었다.
정리하자면
- lsh의 threshold(비슷한 정도) 값을 낮춰서 좀더 많이 묶이게 하자.
- 기준치를 낮춰서 시작하되, 갈수록 content(title_list)가 길어지므로 threshold 값을 증가
- 과정이 동일하니까 묶이지 않을때까지 묶어보자.
위에서 진행했던 과정과 마지막에 서술한 로직을 종합해서 코드로 만들어보자
# 클러스터링 순서 # 1.데이터 불러오기 및 간단한 전처리 df = pd.read_pickle("./data/article_contents_20211010.pkl") df = df.drop_duplicates(['title','mdName','content']) # 중복제거 drop_list = [] for index, content in enumerate(df['content']): content = contents_preprocessing(content) if content == "" or len(content) == 0: drop_list.append(df.index[index]) df = df.drop(drop_list) # 내용이 비었다면 제거 df.index = range(len(df)) # 2. 초벌 군집화 lsh = MinHashLSH(threshold=0.8, num_perm=128) mh_list = [] for i, row in tqdm(df.iterrows(), total = len(df), desc="minhash_lsh_1"): content = row['content'] content_sample = contents_preprocessing(content) token_set = set() for index in range(0, len(content_sample), 10): token = content_sample[index : index+10] if len(token) < 10: continue token_set.add(token) mh = MinHash(num_perm = 128) for token in token_set: mh.update(token.encode('utf8')) mh_list.append(mh) lsh.insert(i,mh) sim_list = [] for i, mh in enumerate(mh_list): result = lsh.query(mh) sim_list.append(result) df['sim_document'] = sim_list cluster_list = [] visited = set() for index, row in tqdm(df.iterrows(), total=len(df), desc="clustering"): if index in visited: continue else: sim_dict = dict() sim_dict["title"] = row['title'] title_list = [] sim_documents = row['sim_document'] sim_dict['sim_index'] = sim_documents sim_documents = sorted(sim_documents) for s_index in sim_documents: if s_index == index: visited.add(s_index) continue else: s_title = df['title'][s_index] title_list.append(s_title) visited.add(s_index) if len(title_list) == 0: continue sim_dict["sim_document"] = title_list cluster_list.append(sim_dict) # 3. 안묶일때까지 군집화 n = 1 #title / content = title_concat_string / sim_document_index 구성 threshold = 0.4 while True: data = [] for info in cluster_list: title = info['title'] sim_index = info['sim_index'] sim_document = info['sim_document'] content = "" #title + sim_document_title concat for sim_title in sim_document: content += sim_title+" " content += title pattern = r'[^ a-zA-Z가-힣0-9]' content = re.sub(pattern,"",content) temp_list = [title, content, sim_index] data.append(temp_list) filter_df = pd.DataFrame(data, columns=['title','content','sim_index']) # content = title_concat_string 을 통해 lsh = MinHashLSH(threshold=threshold, num_perm=10) mh_list = [] for i, row in tqdm(filter_df.iterrows(), total = len(filter_df), desc="{}th_clustering".format(n)): content = row['content'] token_set = set(content.split()) mh = MinHash(num_perm = 10) for token in token_set: mh.update(token.encode('utf8')) mh_list.append(mh) lsh.insert(i,mh) sim_list = [] for i, mh in enumerate(mh_list): result = lsh.query(mh) sim_list.append(result) filter_df['sim_cluster'] = sim_list # 묶인게 없으면 탈출하기 위해서 sim_count = 0 for sim in sim_list: sim_count += len(sim) if sim_count == len(sim_list): break else: print("cluster exist") print(n,"번째 군집화 진행 theshold=", threshold) n+=1 threshold += 0.1 if threshold >= 0.9: break cluster_list = [] visited = set() for index, row in filter_df.iterrows(): if index in visited: continue title = row['title'] sim_index = row['sim_index'] index_set = set() #클러스터 된 index들을 모을 set index_set.update(set(sim_index)) sim_cluster = row['sim_cluster'] for cluster in sim_cluster: if cluster == index: visited.add(cluster) continue else: other_index = filter_df['sim_index'][cluster] index_set.update(set(other_index)) visited.add(cluster) index_list = list(index_set) title_list = [] for i in index_list: sim_title = df['title'][i] title_list.append(sim_title) sim_dict = dict() sim_dict['title'] = title sim_dict['sim_index'] = index_list sim_dict['sim_document'] = title_list cluster_list.append(sim_dict) # 4. 결과 저장 cluster_list = sorted(cluster_list, key=lambda x : -len(x['sim_index'])) with open('./data/cluster_sample_20211011_2.json', 'w', encoding='UTF-8-sig') as file: file.write(json.dumps(cluster_list,indent=4,ensure_ascii=False)) print("result save complete")아 결과 값을 보기 전에 데이터를 바꿨다. 20210723 네이버 뉴스로 진행하니
글을쓰는 시점(20211011) 과 달라서 잘 묶인건지 아닌건지 헷갈려서 20211010의 네이버 뉴스들로 바꿨다.


하지만 여전히 안 묶이는 문제가 있었다.

각자 약 2백여개의 기사가 묶였지만 둘이 비슷하다고 판단하진 않았던것 같다.
threshold를 일정 값이상이 넘을때, 특정 상수값으로 고정(ex. 0.8) 해두고, 반복수를 제한해서 비교하는 방법도 나쁘지 않을 것 같다.
아쉬운점으로는 알고리즘을 이해했지만, 사용하는 모듈에 대해 좀 더 자세한 조사는 하지 않았다. (다른 할게 많아서..) 그래서 좀더 알고 쓰는게 좋을 것 같다.
java 버전의 minhas lsh도 알아놔서 나중에 기사 클러스터링 서비스를 만들어 보고 싶다.
물론 지금 python 으로 진행한 것에서 좀 더 정확도를 높이고, 묶이지 않은 동일 주제 기사들을 묶는데 주력해야겠지만...
그래도 재밌었다!
참고
https://haandol.github.io/2019/05/28/lsh-minhash-explained.html
https://jeongchul.tistory.com/604
https://towardsdatascience.com/understanding-locality-sensitive-hashing-49f6d1f6134