java HashMap source code 살펴보기
source code의 주석 살펴보기
(파파고로 번역을 돌렸다!)
1번째 주석 -> HashTable 구현체 고, key값으로 null 지원한댄다.(순서는 보장 x)
Hash table based implementation of the " Map " interface.
This implementation provides all of the optional map operations,
and permits " null " values and the " null " key.
(The " HashMap " class is roughly equivalent to " Hashtable " ,
except that it is unsynchronized and permits nulls.)
This class makes no guarantees as to the order of the map;
in particular, it does not guarantee that the order will remain constant over time.
" 맵 " 인터페이스의 해시 테이블 기반 구현입니다.
이 구현은 모든 선택적 맵 작업을 제공하며 " null " 값과 " null " 키를 허용합니다.
( " 해시맵 " 클래스는 동기화되지 않고 null을 허용한다는 점을 제외하고 대략 " Hashtable " 과 동일합니다.)
이 클래스는 맵의 순서에 대해 보장하지 않으며, 특히 시간이 지남에 따라 순서가 일정하게 유지됨을 보장하지 않습니다.
2번째 주석 -> 빠르게 찾으려면 너무 크게 만들지 마라!
This implementation provides constant-time performance for the basic operations
( " get " and " put " ),
assuming the hash function disperses the elements properly among the buckets.
Iteration over collection views requires time
proportional to the " capacity " of the " HashMap " instance
(the number of buckets) plus its size (the number of key-value mappings).
Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
이 구현은 기본 작업에 대해 일정한 시간 성능을 제공합니다. ( " get " 및 " put " ),
해시 함수가 버킷 간에 요소를 적절하게 분산시킨다고 가정합니다.
컬렉션 뷰에 대해 반복하려면 시간이 필요합니다.
" 해시맵 " 인스턴스의 " 용량 " 에 비례합니다.
(버킷 수)에 해당 크기(키-값 매핑 수)를 더한 값입니다.
따라서 반복 성능이 중요한 경우 초기 용량을 너무 높게(또는 부하율을 너무 낮게) 설정하지 않는 것이 매우 중요합니다.
3번째 주석 -> 초기 용량하고 table 한 칸당 value 채울 비율이 성능에 영향을 미친다.
(알아서 적당히 초기화해놨다!)
An instance of "HashMap" has two parameters that affect its performance:
"initial capacity" and "load factor" .
The "capacity" is the number of buckets in the hash table,
and the initial capacity is simply the capacity at the time the hash table is created.
The "load factor" is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
When the number of entries in the hash table exceeds the product of the load factor and the current capacity,
the hash table is "rehashed" (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
“HashMap”의 인스턴스에는 성능에 영향을 미치는 두 가지 매개 변수가 있습니다.
“초기 용량” 및 “부하 계수”.
“capacity”는 해시 테이블의 버킷 수입니다.
초기 용량은 단순히 해시 테이블을 생성할 때의 용량입니다.
“부하 계수”는 용량이 자동으로 증가하기 전에 해시 테이블이 얼마나 가득 찰 수 있는지를 측정하는 척도이다.
해시 테이블의 항목 수가 로드 팩터의 곱과 현재 용량을 초과할 경우,
해시 테이블은 “해시”되므로(즉, 내부 데이터 구조가 재구성됨) 해시 테이블은 버킷의 약 두 배를 갖는다.
4번째 주석 -> table(배열) 내부에 value 저장될 때 대충 0.75 정도 차면 재해시(re-hash) 했다!
As a general rule,
the default load factor (.75) offers a good tradeoff between time and space costs.
Higher values decrease the space overhead but increase the lookup cost
(reflected in most of the operations of the "HashMap" class, including "get" and "put").
The expected number of entries in the map and its load factor should be taken into account
when setting its initial capacity,
so as to minimize the number of rehash operations.
If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
일반적으로, 기본 하중 계수(. 75)는 시간과 공간 비용 사이에서 좋은 균형을 제공합니다.
값이 클수록 공간 오버헤드는 감소하지만 조회 비용은 증가합니다.
(“get” 및 “put”을 포함한 “HashMap” 클래스의 대부분의 작업에 반영됩니다.)
지도에서 예상되는 항목 수와 하중 계수를 고려해야 합니다.
초기 용량을 설정할 때, 재해시 작업의 수를 최소화하기 위해.
초기 용량이 최대 항목 수를 로드 팩터로 나눈 값보다 크면 재해시 작업이 발생하지 않습니다.
5번째 주석 -> 첨부터 좀 크게 만들면 빠를 수도?
If many mappings are to be stored in a "HashMap" instance,
creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table.
Note that using many keys with the same {@code hashCode()} is a sure way to slow down performance of any hash table.
To ameliorate impact, when keys are Comparable, this class may use comparison order among keys to help break ties.
“HashMap” 인스턴스에 많은 매핑을 저장할 경우 충분히 큰 용량으로 생성하면 테이블을 확장하는 데 필요한 자동 재해시를 수행하는 것보다 매핑을 더 효율적으로 저장할 수 있습니다.
동일한 {hashCode()}에 많은 키를 사용하는 것이 모든 해시 테이블의 성능을 저하시킬 수 있는 확실한 방법입니다.
키가 {Comparable}인 경우 영향을 개선하기 위해 이 클래스는 키 간의 비교 순서를 사용하여 연결을 끊을 수 있습니다.
6번째 주석 -> 동기화되지 않기에 Thread 작업 시 주의!
"Note that this implementation is not synchronized."
If multiple threads access a hash map concurrently, and at least one of
the threads modifies the map structurally, it "must" be synchronized externally.
(A structural modification is any operation that adds or deletes one or more mappings;
merely changing the value associated with a key that an instance already contains is not a structural modification.)
This is typically accomplished by synchronizing on some object that naturally encapsulates the map.“이 구현은 동기화되지 않습니다.”
여러 스레드가 동시에 해시 맵에 액세스 하는 경우 다음 중 하나 이상 스레드가 맵을 구조적으로 수정하고,
외부에서 “반드시” 동기화해야 합니다.
(구조 수정은 하나 이상의 매핑을 추가하거나 삭제하는 작업입니다.
인스턴스에 이미 포함된 키와 관련된 값을 변경하는 것은 구조적인 수정이 아닙니다.)
이것은 일반적으로 맵을 자연스럽게 캡슐화하는 일부 개체에서 동기화함으로써 달성된다.
source code 살펴보기
hashMap은 hashTable 형태로 구현되어있고, key- value (chain) 형식으로 구현되어있다.
value는 Node라는 새로운 객체로 변경되어 저장되고,
동일한 키값으로 들어올 경우 변경 혹은 연결(Linked List or Tree) 되어 저장된다.
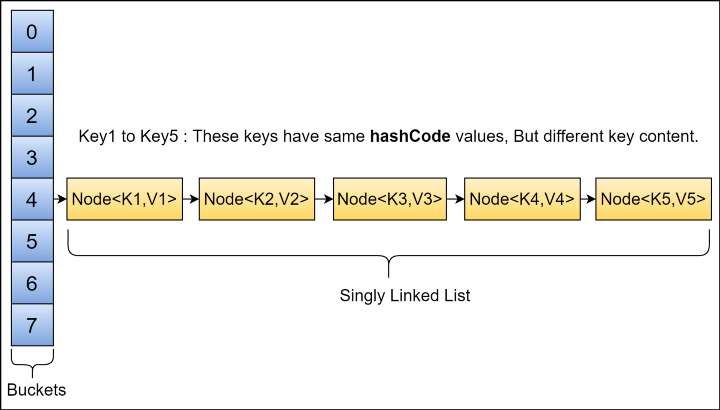
먼저 Node 객체 선언, 함수를 살펴보자.
- Map.Entry의 구현체
- Node 객체 초기화
final int hash;
final K key;
V value;
Node < K, V > next;
Node(int hash, K key, V value, Node < K, V > next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}- hash : 해쉬 값
- key, value : key값(사용자가 입력한 원래 값), 키에 대응되는 value값(사용자가 입력한 원래 값)
- Node <k, v> next : 해당 Node의 다음에 오는 Node를 가리키는 포인터
> 클래스 내 함수들
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}- hashCode()
- key 값과 value 값의 해쉬코드를 ^ (xor) 연산
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}- setValue(V newValue)
- setValue를 통해 value 변경 가능, 하지만 key값 변경 불가
public final boolean equals(Object o) {
if (o == this) return true;
if (o instanceof Map.Entry) {
Map.Entry < ? , ? > e = (Map.Entry < ? , ? > ) o;
if (Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue()))
return true;
}
return false;
}- equals(Object o)
- Node 객체 간의 동일 객체 판단
- Entry 객체 인지 instanceof 로 검사
- key hash와 value hash 비교
- Node 객체 간의 동일 객체 판단
- 전체 코드
static class Node < K, V > implements Map.Entry < K, V > {
final int hash;final K key;V value;Node < K,V > next;
Node(int hash, K key, V value, Node < K, V > next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final String toString() {
return key + "=" + value;
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this) return true;
if (o instanceof Map.Entry) {
Map.Entry < ? , ? > e = (Map.Entry < ? , ? > ) o;
if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true;
}
return false;
}
}
테이블 내 저장되는 Node 클래스를 확인했으니
Map에서 자주 사용하는 put, get, remove 정도만 살펴보자… (왜냐면 HashMap code는 너무 길어서…)
HashMap 클래스 선언 시 초기에 선언되는 테이블의 형태는
transient Node<K,V>[] table;Node 클래스 배열 형태를 가지고 있다.
배열의 특정 인덱스에 값을 넣고,
접근 시 인덱스로 접근하기 때문에 O(1)의 시간이 걸리는 것 아닐까? 하고 선언된 자료형을 통해 유추할 수 있다.
put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}HashMap 클래스에서 제일 많이 사용하는 함수인 put이다. 근데 해당 함수의 진짜는 putVal 에 숨겨져 있다. 그전에 파라미터로 넘어가는 hash(key)를 살펴보자.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
key값이 null 이 아닐 경우, 해당 객체의 해쉬 코드 함수를 통해 해쉬값을 반환받는 걸 볼 수 있다.
putVal 함수는 (key의 해쉬 값, key, value,?,?) 값을 이용해 해쉬 테이블에 넣는다.
putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
위 put 함수에서 false, true로 들어간 자리의 파라미터에 대한 설명이 sourcecode에 나와있다.
onlyIfAbsent if true, don't change existing value
-> onlyIfAbsent 가 true 값인 경우, 기존 값을 변경하지 않는다.put에서 false로 설정된 걸 보면, 새로운 값이 들어올 때 기존 값을 변경 한다는 말
evict if false, the table is in creation mode.
-> evict 가 false 인경우, 테이블은 생성모드
put에서 true 이므로, 테이블은 생성 모드가 아니다. -> 이것이 의미하는 건 뭔지 모르겠다.
이어서 putVal 코드를 살펴보자
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
이전에 살펴본 ArrayList에 비해 복잡하고 한눈에 들어오지 않는다. 우선 if-else 별로 어떤 조건이고 무엇이 동작하는지 쪼개 보자.
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //tab = resize() 함수 실행
맨 처음 table은 비어있기 때문에 resize() 함수를 통해 테이블 초기화를 해준다.
(resize 함수는 함수 이름처럼 테이블을 재배열하기에 초기화에만 쓰이지 않는다.)
resize()
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
또 코드가 와장창 나왔다. 다시 한번 흐름을 적어보자.
현재 put -> putVal -> if(table==null) -> resize 순으로 흘러간다. resize 함수도 if-else로 쪼개 보자.
Node<K,V>[] oldTab = table; // HashMap 클래스의 MapTable
int oldCap = (oldTab == null) ? 0 : oldTab.length; //현재 저장된 Node의 개수 반환
int oldThr = threshold; // 배열의 용량
int newCap, newThr = 0; // 새로 변경될 capacity, Threahold
첫 if-else는 3 부분으로 나눠져 있다.
if (oldCap > 0) { //<- 현재 저장된 Node의 개수를 보자
if (oldCap >= MAXIMUM_CAPACITY) { //<- 최대 저장크기보다 크면?
threshold = Integer.MAX_VALUE; //<- threshold를 integer 최대값으로 변환
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) // <- 초기 설정된 capacity보다 현재 capacity 값이 많다면 공간을 늘려야됌
newThr = oldThr << 1; // double threshold <- threshold를 2배 늘려준다.
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
위에서 말했듯이 resize 함수의 경우,
초기화 이외에도 기존 크기 넘어서 데이터를 담으려 할 땐
재배열이 필요하기 때문에
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; <- Node 형의 배열
table = newTab; <- resize시 새로운 Node배열 선언
// 기존것이 존재할때 기존 배열의 값을 newTab으로 옮기는 작업 수행
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
// 기존 배열의 index 별 해당 공간이 비어있는지 체크, 비어있지 않다면
oldTab[j] = null; // 해당 공간 내 데이터 제거!
if (e.next == null) // <- next == null 이면 Node가 자기 자신 외 없다는 얘기가 된다.
newTab[e.hash & (newCap - 1)] = e; //<-
else if (e instanceof TreeNode) // 현재 Node가 Tree형인지 체크, 맞다면!
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // tree를 부신다
else { // preserve order -> Tree가 아니면서 Node만 존재하는게 아니라면!(=Linked List)
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
} // LinkedList에 Node를 연결해준다.
}
}
}
return newTab; // 변경이 완료된 새 table을 반환한다.
이렇게!
put -> putVal -> table==null -> resize의 순서를 끝냈다.
다시 putVal 함수로 돌아가 그다음 if-else를 살펴보자.
if ((p = tab[i = (n - 1) & hash]) == null)
// table의 해당 인덱스에 값이 존재하지 않는 경우,
tab[i] = newNode(hash, key, value, null); // Node를 새로 생성후 해당 index에 삽입한다.
테이블에 (없다면 위 if 작업에서 생성 및 재배열) 특정 인덱스가 비어있다면
해당 자리에 새로운 Node를 생성해 삽입해준다.
만약 해당 자리에 값이 이미 존재한다면? (그 말인 즉, 이미 존재하는 키값이라면?)
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
3가지 분기가 존재한다.
- 해쉬값이 동일, 키값이 동일 → 완전히 동일한 키값이 들어왔다? ⇒ 값을 변경해준다.
- 1번 경우가 아니라면, 해쉬는 같지만 키값이 동일하지 않고!, Node가 Tree형이면 Tree에 새로 연결 treeifyBin(tab, hash)
- 1번 경우가 아니고, Tree형 Node도 아니라면, LinkedList 이므로 Node 연결
- 하지만 Link길이가 Tree로 만들 정도로 길다면? → treeifyBin(tab, hash)
- 그 정도로 길지 않다면? → NewNode() 생성후 마지막에 연결
여기서 의문!
지금까지 나는 HashMap에 값을 넣을 때 key값은 유일하다고 여겼는데
Hash값인 만큼 동일한 Hash가 생길 수 있다는 점을 간과했었다.
Hash값이 동일하고! 그렇기 때문에 1번과 2,3번의 분기점이 나뉜다.
String의 경우, hash값이 동일하게 나올 수 있는지 여부는 아래 링크를 통해 확인했다.
[Java/Tip] String.hashCode()는 유일한 값을 반환할까?
[Java/Tip] String.hashCode()는 유일한 값을 반환할까?
요즘에도 댓글이 달려, 내용을 좀 다듬었습니다. HashMap 내부 소개와 더불어 hashCode()에 대한 설명을 하려다보니 내용에 혼돈이 있었습니다. 해당 내용은 Java7 을 기준으로 작성된 내용입니다. Java
blog.ggaman.com
2, 3번 분기의 경우
배열의 특정 칸에 Node개수가 클래스가 정한 threshold 값을 넘으면 LinkedList에서 Tree 형태로 바뀐다.
마찬가지로 해당 칸에 Node를 제거해 개수가 threshold 보다 작아지면 다시 LinkedList로 바뀐다.
어떤 블로그를 확인하니 put 함수가 O(1)의 시간이 걸린다고 적어놨던데 코드를 확인해보면 안 그런 거 같은데…
(2, 3번의 경우 실제로 길이가 길어질 경우, 재배치를 해야 하고 그럼 O(1)이 아닌데…)
이렇게 간단하게 put 함수를 살펴봤다. (간단하지 않다… 정리하기 힘들다…)
get
put과 달리 get 함수는 굉장히 심플하다.
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
- table이 없다면 → null
- table이 존재하고, 해당 table 배열의 길이가 0 보다 크고, 배열의 해당 자리에 값이 null 이 아니면!
- Hash값이 동일하고, 키값이 정확히 같다면 해당 객체 반환!
- a 케이스가 아니고, 값이 존재하면
- TreeNode라면 Tree 순회해서 값 여부 판단 및 객체 반환
- 아니라면 LinkedList를 순회하면서 해당 객체를 찾고 반환
put 보다는 덜 어지럽다.
containsKey
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
심플하다.
get에서 사용한 getNode 함수를 이용해 반환 값이 null이 아니라면 값이 있는 거니까!
remove
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
HashMap에서 remove를 할 때 기대하는 건 내가 지정한 key에 value 값이 지워지도록 동작하는 것이다.
실제로 그렇게 동작하는지 removeNode 함수를 보자.
removeNode(hash(key), key, null, false, true)
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
또 코드가 와장창 나왔다.
그래도 put 함수보다는 적게 써져있다고 위로를 하면서 살펴보자
- 테이블이 존재하고, (tab = table)!= null)
테이블의 값이 들어있으며, (n = tab.length) > 0
key 값에 해당하는 값이 있는지 먼저 확인한다. (p = tab [index = (n - 1) & hash])!= null)- hash값이 같고, 키의 객체와 값이 완전히 동일하다면! → node = p
p.hash == hash && ((k = p.key) == key || (key!= null && key.equals(k))) - 그게 아니라면 (hash는 같지만, 값이 아니네?) (e = p.next)!= null
- TreeNode면 node = ((TreeNode <K, V>)p). getTreeNode(hash, key)
- LinkedList 면 마지막 Node에 연결해준다.
- hash값이 같고, 키의 객체와 값이 완전히 동일하다면! → node = p
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
node가 null이 아니면 해당 값을 테이블 내에서 remove! 해야 한다.
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
- TreeNode면 TreeNode의 remove 함수에 맡기기!
- LinkedList면 단순히 포인터 값을 p.next로 옮겨버리기!
put과는 반대의 작업을 하는 걸 알 수 있다. (분해는 조립의 역순…)
위 함수들 이외도 HashMap의 여러 다른 함수가 존재하지만 나는 여기까지…
참고
- Java HashMap은 어떻게 동작하는가? [https://d2.naver.com/helloworld/831311]
- [Java] HashMap이란 무엇인가? [https://devlog-wjdrbs96.tistory.com/241]
- The Java HashMap Under the Hood [https://www.baeldung.com/java-hashmap-advanced#collisions-in-the-hashmap]
- [자료구조] 코드로 알아보는 java의 Hashmap [https://sabarada.tistory.com/57?category=826240]
- jdk source code [https://github.com/AdoptOpenJDK/openjdk-jdk8u/blob/master/jdk/src/share/classes/java/util/HashMap.java]
- Java HashMap - HashMap in Java [https://www.digitalocean.com/community/tutorials/java-hashmap]
- String hashCode의 유일성? [https://blog.ggaman.com/916]
- 이것만 알면 해시맵(HASHMAP) 정복 가능 - HASHMAP의 특징, 사용법 예제[https://reakwon.tistory.com/151]