
문제 풀이 정리
문제 설명
매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같이 특별한 방법으로 섞어 새로운 음식을 만듭니다.
섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
Leo는 모든 음식의 스코빌 지수가 K 이상이 될 때까지 반복하여 섞습니다.
Leo가 가진 음식의 스코빌 지수를 담은 배열 scoville과 원하는 스코빌 지수 K가 주어질 때, 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 섞어야 하는 최소 횟수를 return 하도록 solution 함수를 작성해주세요.
제한 사항
- scoville의 길이는 2 이상 1,000,000 이하입니다.
- K는 0 이상 1,000,000,000 이하입니다.
- scoville의 원소는 각각 0 이상 1,000,000 이하입니다.
- 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다.
입출력 예
scoville / K / return
| [1, 2, 3, 9, 10, 12] | 7 | 2 |
입출력 예 설명
- 스코빌 지수가 1인 음식과 2인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
새로운 음식의 스코빌 지수 = 1 + (2 * 2) = 5
가진 음식의 스코빌 지수 = [5, 3, 9, 10, 12] - 스코빌 지수가 3인 음식과 5인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
새로운 음식의 스코빌 지수 = 3 + (5 * 2) = 13
가진 음식의 스코빌 지수 = [13, 9, 10, 12]
모든 음식의 스코빌 지수가 7 이상이 되었고 이때 섞은 횟수는 2회입니다.
코드
def solution(scoville, K):
answer = 0
import heapq
num_list = sorted(scoville)
min_num = min(num_list)
first, second = 0,0
if 0 in num_list: # 0은 계산시 값 변화x 그래서 제외
num_list.remove(0)
if K == 0: # 최댓값이 0이면 볼 필요없이 return 0
return answer
while min_num <= K:
if len(num_list) > 1: # 개수가 2 이상부터
first = heapq.heappop(num_list) # 자료구조 heap을 이용해 최소값 반환
second = heapq.heappop(num_list)
else: # 아니면 -1
return -1
new_num = first + (second * 2) # 지수 재계산
heapq.heappush(num_list, new_num) #heap 구조에 재 삽입
min_num = num_list[0]
answer+=1 # 루프 한번에 +1씩 카운트
return answer
문제 넋두리
처음에 문제를 보곤 그다지 어렵다 느껴지지 않았다
재계산하고 다시 배열에 넣은 다음, 정렬하고 다시 최솟값 두개 뽑아 계산하고...의 반복일테니까
값이 나올때까지 돌리면 되겠구나 싶어 코딩했었다.
정답은 나왔지만,,, 시간 효율성에서 탈락이였다.
문제 유형에 heap이라고 적혀 있으니 heap을 써보자 해서
구글에 python...heap...적어서 나온 모듈을 사용했다.
풀고 나서 자료구조에 대해서 너무 무지한것 같아 이번 기회에 하나씩 정리해보자 싶어 이렇게 써본다

먼저 위키 피디아를 살펴보자
https://ko.wikipedia.org/wiki/%ED%9E%99_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
힙 (자료 구조) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 1부터 100까지의 정수를 저장한 최대 힙의 예시. 모든 부모노드들이 그 자식노드들보다 큰 값을 가진다. 힙(heap)은 최댓값 및 최솟값을 찾아내는 연산을 빠르게
ko.wikipedia.org
힙이란?
위키백과에 써있듯이
최대,최소를 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리의 자료구조
- 부모 노드와 자식 노드간의 대소관계가 성립
- 부모노드 > 자식노드 => 최대힙, 루트가 최댓값이 됌
- 부모노드 < 자식노드 => 최소힙, 루트가 최솟값이 됌
- i번째 노드의 왼쪽 자식노드의 위치는 2i가 되며, i번째 노드의 오른쪽 자식노드의 위치는 2i+1이고, 또한 i번째 노드의 부모노드의 위치는 i/2
- 시간 복잡도는 O(logN)
- 트리지만 배열에 저장해 사용
그럼 이제 코드로 살펴보자
(구글링) 파이썬 코드는 https://airsbigdata.tistory.com/146
[Python 자료 구조] 힙 (Heaps)
#힙과 이진 탐색 트리 비교 구분 힙 이진 탐색 트리 원소들은 완전히 크기 순으로 정렬되어 있는가? X O 특정 키 값을 가지는 원소를 빠르게 검색할 수 있는가? X O 부가의 제약 조건은 어떤 것인가
airsbigdata.tistory.com
여기 잘 정리 되어있고, 나의 경우 해당 코드를 이해하면서 다시 정리 하는 차원에서 써본다.
삽입시
- 배열의 마지막에 데이터 삽입
- 부모노드와 대소 비교하면서 자리 바꾸기
삽입코드
def insert(data, number):
data.append(number) #배열 마지막에 삽입
index = len(data) - 1 #해당 데이터의 위치
while index != 0: #위치가 젤 상단이 될때까지 반복
parentIndex = index // 2 # 부모노드 위치
if data[parentIndex] < data[index]: #대소비교 조건 만족
data[parentIndex], data[index] = data[index], data[parentIndex] #자리변경
index = parentIndex # 해당 데이터 위치 변경
else:
break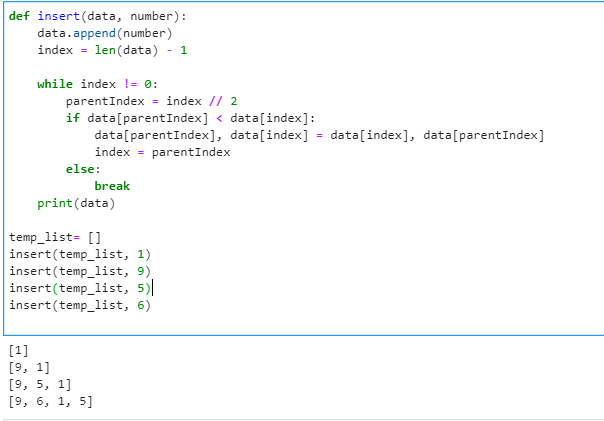
데이터 삭제시
- 루트 노드 삭제
- 마지막 노드를 루트 노드로 올린뒤, 재 정렬
- 재정렬시, 자식 중 더 큰 값과 바꾸기
- 위 과정 반복
삭제 코드
def rearrangement(data, index): # 재정렬 함수
left = index*2+1 # 배열은 0부터 시작이라...
right = index*2+2
large_index = index
if left < len(data) and data[left] > data[large_index]:
large_index = left # 왼쪽 자식 노드와 대소 비교후 크다면 index 값 저장
if right < len(data) and data[right] > data[large_index]:
large_index = right # 오른쪽 자식 노드와 대소 비교후 크다면 index값 저장
if index != large_index: # index값과 저장된 large_index가 다르면 위치 변경
data[index], data[large_index] = data[large_index], data[index]
rearrangement(data, large_index) # 변경된 노드부터 재정렬 재귀 호출
def delete(data): # 데이터 지우기 함수
delete_number = -1
if len(data) > 1: # 1개 이상인 경우
data[0], data[-1] = data[-1], data[0] # 마지막 노드와 루트 노드 변경
delete_number = data.pop(-1) #마지막 반환(제일 큰 값)
rearrangement(data, 0) # 재정렬
elif len(data) == 1:
delete_number = data.pop(0)
else:
print("no data")
return delete_number
어렵다 어려워...
정리끝~
'algorithm > programmers' 카테고리의 다른 글
| 큰 수 만들기 [프로그래머스] (0) | 2021.07.02 |
|---|---|
| 2개 이하로 다른 비트 [프로그래머스] (0) | 2021.06.27 |
| 스킬트리 [프로그래머스] (0) | 2021.05.17 |
| 약수의 개수와 덧셈 [프로그래머스] (0) | 2021.05.15 |
| n진수 게임 [프로그래머스] (0) | 2021.05.14 |




댓글