네이버 영화평 가져오기 설명
들어가기 전 네이버의 robots.txt 에 대해 먼저 숙지하자.

사용 언어 및 모듈
- python 3.7
- request = request 요청을 보내 html 값을 가져오기
- bs4 (BeautifulSoup) = 받은 html 값을 요소별로 구분하기
- pandas = 구분한 값을 보기 편하게
- tqdm = 얼마나 진행되었는지 보기 위해
- random = 요청 보내는 시간을 불규칙하게 조절
- time = 한번 요청을 보내고 잠시 대기 하기 위해
네이버 영화평 corpus 가 이미 존재한다.
(ref. github.com/e9t/nsmc)

총 20만개로 다들 이걸로 모델도 만들고, 감성분석도 수행하지만...
나는 데이터가 좀 더 많이 있었으면 좋겠다고 생각했다.
그래서 다들 하는 것처럼 수집을 해보기로 했다.
데이터를 가져올 url은 여기다.
url : https://movie.naver.com/movie/point/af/list.nhn?&page=1
평점 : 네이버 영화
네티즌 평점과 리뷰 정보 제공
movie.naver.com

여기서 내가 원하는 부분은 저 한줄평을 전부 가져오는것이다.
예시로 request를 날려보자.
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/point/af/list.nhn?&page=1'
html = requests.get(url)
soup = BeautifulSoup(html.content, 'html.parser')
subject_list = soup.find_all('td',{'class':'title'})날라온 결과값을 살펴보자.

이제 필요한 부분만 챙겨보자. 한줄 평만 가져가고 싶기 때문에 soup(tag).text 함수를 이용하고 싶지만
제목과 평점 등의 다른 결과까지 함께 가져오게 된다.
그렇기 때문에
subject_list[0].find('a').extract() #'a' tag 부분을 제거
subject_list[0].find('div').extract() #'div' tag 부분을 제거
subject_list[0].text # 이제 text 추출결과는

필요없는 문자들이 너무 많기 때문에 제거해준다.

대충 만드느라 replace문이 거지같지만 이걸 읽는 분들은 더 이쁘고 아름답게 제거 할것이라 믿는다.
그럼 이제 page 1개가 아니라 될 수 있는 만큼 가져와보자
import pandas as pd
import time
page_num = 1
review_list = []
url = 'https://movie.naver.com/movie/point/af/list.nhn?&page={}' #page 에 따라 바뀌어야 함
num = 1 # 가져온 한줄평이 몇개나 됐는지 카운트
while(True):
try:
req_url = url.format(page_num) #page 숫자 넣어주기
page_num +=1 # 넣은 뒤엔 page_num 하나 더해주기
#해당 page내 한줄평 가져오기
html = requests.get(req_url)
soup = BeautifulSoup(html.content, 'html.parser')
temp_subject_list = soup.find_all('td',{'class':'title'})
for subject in temp_subject_list:
subject.find('a').extract()
subject.find('div').extract()
text = subject.text.replace("\n\n\n","").replace("\n\t","").replace('\t\t',"").replace("신고\n","")
review_list.append(text)
# 읭? 이건 무슨코드지? 싶은 부분은 아래 설명
if(len(review_list) >= 10000):
df = pd.DataFrame(review_list, columns=['review'])
df.to_pickle('naver_review_small.pkl')
break
else:
if(len(review_list) / 100 > num):
print("제목수 : ",len(review_list))
num+=1
# 요청을 한꺼번에 너무 많이 하는 경우 비정상 접속으로 차단할 수 있기 때문에
# 뜸들이기 0.5초
time.sleep(0.5)
except:
print("error occured!")
break설명이 필요한 부분이 생겼다.
중간에 review_list 변수, 한줄평의 개수가 1만이 넘어가면 멈추고 pandas dataframe으로 저장하게 되어있다.
네이버 영화평의 경우 불러올 수 있는 page를 1000개로 고정시켜놓았다.
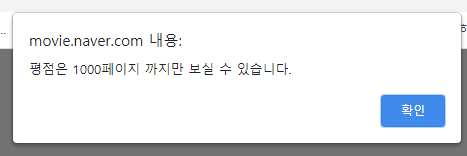
한 페이지에 한줄 평 10개, page limit 1000개 도합 1만 개의 평 밖에 얻을 수 없다.
방법이 없을까? 있다.
두번째 방법
전체 영화 한줄평으로 들어가는 것이 아닌, 한 영화에 대한 한줄평으로 들어가면 조금 더 많이 볼 수 있게 된다.
url : movie.naver.com/movie/point/af/list.nhn?st=mcode&sword=203288&target=after
평점 : 네이버 영화
네티즌 평점과 리뷰 정보 제공
movie.naver.com
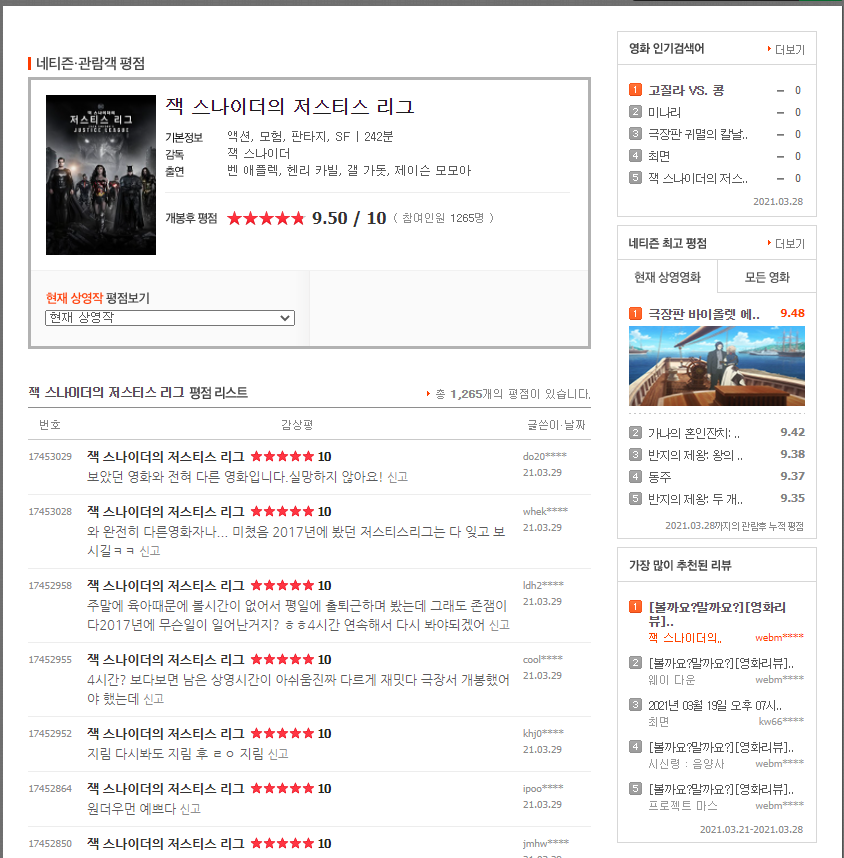
한 영화에 대한 한줄평 역시 page 최대 1000개로 고정되어 있는건 동일하지만, 어벤져스 영화급이 아니라면
생각보다 1만 개의 한줄평을 넘는건 많지 않아보인다.
그렇다면 영화별로 접근을 할 수 있어야 한다.
전체 영화평과 특정 영화의 영화평 페이지 url에 힌트가 있다.
전체 영화평 url : movie.naver.com/movie/point/af/list.nhn?&page=1
특정 영화 영화평 url : movie.naver.com/movie/point/af/list.nhn?st=mcode&sword=203288&target=after
url parameter 부분으로 page 정보 대신 ?st=mcode&sword=203288&target=after 가 추가 되어있다.
그렇다면 저 부분을 추가하면 특정 영화로 접근가능할 것 같은데... 저 정보는 어디있지?

처음에 본 전체 영화평의 데이터 모습이다. 잘보면 영화 제목 a tag에 href 값으로 우리가 원하는 정보가 들어있는 것을 알 수 있다.

한줄 평 가져오기 로직이 수정되게 된다.
1. 영화 url을 전부 가져오기 (추가)
2. 가져온 url을 통해 한줄평 긁어오기 (기존과 동일)
먼저 1번 과정 코드
page_num = 1
movie_list = set()
url = 'https://movie.naver.com/movie/point/af/list.nhn?&page={}'
num = 1
while(True):
try:
req_url = url.format(page_num)
page_num +=1
html = requests.get(req_url)
soup = BeautifulSoup(html.content, 'html.parser')
temp_subject_list = soup.find_all('td',{'class':'title'})
for subject in temp_subject_list:
movie_url = subject.find('a').get('href') # 한줄평 대신 영화 url을 가져오기
movie_list.add(movie_url)
if(page_num >= 1000):
break
else:
if(len(movie_list) / 100 > num): # 몇개쯤 가져왔나 체크하기
print("영화수 : ",len(movie_list))
num+=1
time.sleep(0.5)
except:
print("error occured!")
break
df = pd.DataFrame(movie_list, columns=['movie'])
df.to_pickle('movie_url.pkl')이렇게 구성한 url을 통해 데이터를 가져온 결과

코드를 잘 살펴보면 movie_list 가 list 타입이 아닌 set 타입이다.
전체 한줄평의 경우 한 영화에 다른 사용자가 평을 남길 경우가 존재하기 때문에 중복을 배제하기 위한 조치 이다.
2번 과정 코드
df = pd.read_pickle('./movie_url.pkl') # url 저장된 pickle 파일 불러오기
movie_list = df['movie']
url = "https://movie.naver.com/movie/point/af/list.nhn" # 기본 url
for i, movie_url in enumerate(movie_list): #반복문을 순회하면서...
try:
# "https://movie.naver.com/movie/point/af/list.nhn" + movie_url
# url 을 붙혀 특정영화 한줄평으로 이동
target_url = url+movie_url
target_url += "&page={}" # page를 옮기기
page_num = 1
review_list = []
# do something!
except:
print("error occured_2")
break#do something 부분을 채워 넣어야 하는데 이 부분은 앞서 만들어 보았다. 해당 부분을 채워넣은 코드로 다시 보자
df = pd.read_pickle('./movie_url.pkl')
movie_list = df['movie']
url = "https://movie.naver.com/movie/point/af/list.nhn"
for i, movie_url in enumerate(movie_list):
if(i < 2092):
continue
try:
target_url = url+movie_url
target_url += "&page={}"
page_num = 1
review_list = []
# do something
# 마지막 페이지에 도달할 경우 계속 같은 페이지가 로딩 되기때문에
# 지금 가져온 한줄평과 이전 한줄평이 같은 데이터인지 비교위해 선언
pre_temp_subject_list = []
num = 1
while(True):
try:
req_url = target_url.format(page_num)
page_num += 1
html = requests.get(req_url)
soup = BeautifulSoup(html.content, 'html.parser')
temp_subject_list = soup.find_all('td',{'class':'title'})
for subject in temp_subject_list:
# subject.find('a').extract()
# subject.find('div').extract()
score = subject.find('em').text
subject.find('a').extract()
subject.find('div').extract()
text = subject.text.replace("\n\n\n","").replace("\n\t","").replace('\t\t',"").replace("신고\n","")
if(text == '\n' or text == " "):
continue
review_list.append([text, score])
if(page_num >= 1000): # page가 1000 이상일 경우 exit
break
elif(len(temp_subject_list) < 10): # 마지막 page 한줄평이 10개 안될경우 exit
break
elif(pre_temp_subject_list == temp_subject_list): # 가져온 평과 이전 평이 같은 경우 exit
break
else:
if(len(review_list) / 1000 > num):
num+=1
pre_temp_subject_list = list(temp_subject_list)
time.sleep(random.uniform(0.1,0.25)) # 0.1 ~ 0.25초 사이로 랜덤하게 쉬게 하기 위한 부분
except Exception as e:
print("error occured_1", e)
break
# 영화 하나가 완료될때 마다 해당 영화의 index 값으로 한줄평 dataframe으로 저장
df = pd.DataFrame(review_list, columns = ['review','score'])
df.to_pickle('E:/movie_review/movie_{}_pkl'.format(i))
# do something end
except:
print("error occured_2")
break
나의 경우 약 2천개의 영화를 긁어오는데 4~5일 정도 걸린것 같다.
결과
영화 약 2천개에서 총 한줄평 약 7백만개의 데이터를 얻을 수 있었다.
아쉬운점
- 시간이 너무 오래 걸렸다.
-> 빠르게 하기 위해선 여러개의 프로세스를 띄워 동작하게 만들면 가능하지 않을까?
- 전체 영화에 대해 수행 한 것이 아니다.
-> 네이버 영화엔 년도별 영화 정리 페이지가 존재했었던 것 같은데 해당 페이지를 통해 더 많은 정보 조회가 가능할 것 같다.
소감
- 나름 데이터 수집으로 수행했지만 이렇게 많이 될줄 몰랐다. 딥러닝으로 활용하려면 더 많아야 한다지만 개인적 실험 용도로는 충분할 것 같다.
댓글 환영
'text > Python' 카테고리의 다른 글
| 문장 생성 해보기 with. mini-GPT (feat. 네이버 기사 댓글) (0) | 2021.04.21 |
|---|---|
| 문장 생성 해보기 (feat. 네이버 기사 댓글) (0) | 2021.04.02 |
| DOM Based Content Extraction via Text Density 구현해보기 (3) | 2021.04.01 |
| 네이버 기사 댓글 가져오기 (5) | 2021.03.29 |
| Word2Vec parameter 정리 (0) | 2021.02.18 |




댓글