tl;dr
- LRU cache 내부 구조는 double-linked list + dictionary(hash table) 형태로 구성
- python의 collections.OrderedDict 는 double-linked list + dictionary(hash table) 형태
(삽입된 순서를 보장, 순서를 바꿀 수 있는 내부 함수 제공)
오늘 리트코드로 푼 문제의 제목은 LRU Cache 였다.
LRU cache란?
우선, cache가 뭔지 정의되어야겠지?
cpu는 연산할 때 사용하는 데이터를 디스크에서 가져오는데, cpu 연산속도에 비해 디스크에서 데이터 조회해 가져오는 속도는 절망적이다. 그래서 중간에 “디스크보다 훨씬 빠르게 조회할 수 있지만 적재는 적게 되는 공간”을 두는데 그게 바로 메모리다. 그렇지만 cpu 입장에서는 메모리 역시 너무 느리다.
이때 사용되는 “메모리보다 훨씬 빠르게 조회할 수 있지만 적재는 적게 되는 공간”을 cache라고 한다.
그림으로 표현하면
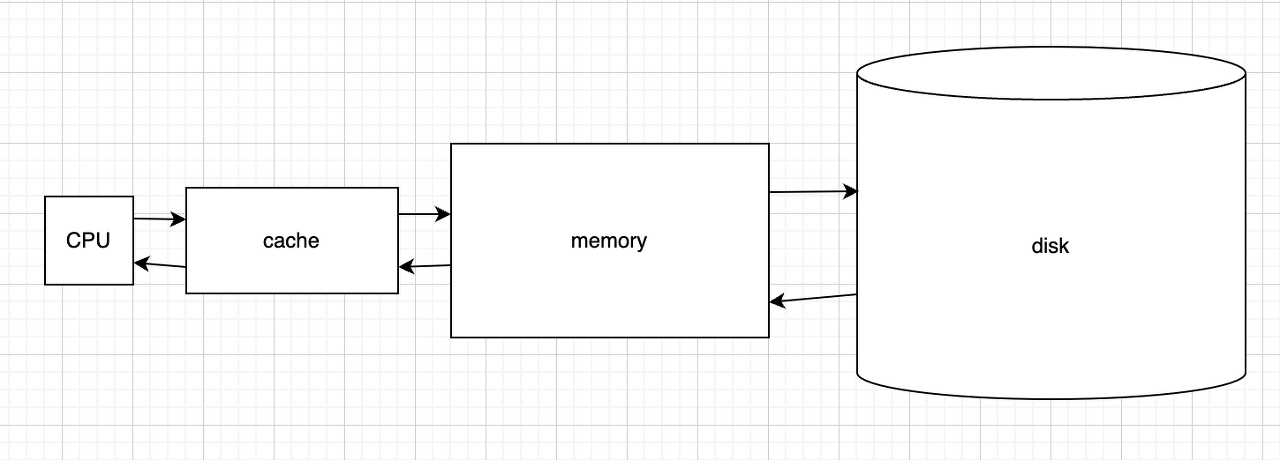
이런 구조다.
cache는 메모리나 디스크에 비해 저장공간이 적기에 cpu가 사용할 데이터를 전부 적재할 수 없다.
그렇기에 차선책으로 여러 전략을 택해 공간에 남길 / 버릴 데이터를 선별하는데
그중 오늘 살펴보는 전략은 LRU (Least recently used) 다.
가장 최근에 선택되는 데이터를 cache에 남기는 방법이다. 자주 조회되는 데이터의 경우, 디스크까지 안 가고 cache를 조회해 사용하므로 빠르게 이용가능하다.
우선 LRU cache에 대한 정보는 이 정도로 정리하고, 오늘의 문제를 살펴보자.
class LRUCache:
def __init__(self, capacity: int):
def get(self, key: int) -> int:
def put(self, key: int, value: int) -> None:
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
캐시를 구현하라는 내용이다.
python의 dictionary를 사용하는 건 확실한데… capacity만큼만 저장이 가능하고… 저장가능 크기가 넘어가면
가장 오래전에 조회된 데이터를 지워야 한다.
풀이 1
가장 오래전이라는 정보는 어떻게 만들고 또 저장해야 할까?
그래서 나는 생성자 부분에 clock이라는 변수를 만들었다.
class LRUCache:
def __init__(self, capacity: int):
self.num_dict = {}
self.clock = 0
self.capacity = capacity
이제 get과 put을 할 때, clock값을 +1 씩 해주면서 저장되는 값으로는 아래와 같이 구성한다.
{
"key" : {
"value" : value,
"clock" : clock
}
}
위와 같이 만들면 get시 현재 clock 숫자를 저장한다. 뒤에 조회할수록 clock의 수가 적은 값을 지우면 된다.
문제는 capacity 만큼 저장되어 있을 때, 새로운 데이터가 들어올 때 발생한다.
가장 적은 clock을 가진 데이터를 찾아야 하는데, dictionary를 순회하면서 찾을 수밖에 없다!!
문제의 조건을 잘 살펴보면
The functions get and put must each run in O(1) average time complexity.
라고 적혀있다.
하지만 나는 방법을 모르기에 O(n)의 방법으로 구성했다.
class LRUCache:
def __init__(self, capacity: int):
self.num_dict = {}
self.clock = 0
self.capacity = capacity
def get(self, key: int) -> int:
self.clock += 1
if key in self.num_dict:
self.num_dict[key]["clock"] = self.clock
return self.num_dict[key]["value"]
else:
return -1
def put(self, key: int, value: int) -> None:
self.delete(key)
self.clock += 1
if key not in self.num_dict:
self.num_dict[key] = {}
self.num_dict[key]["value"] = value
self.num_dict[key]["clock"] = self.clock
self.clock += 1
else:
self.num_dict[key]["value"] = value
self.num_dict[key]["clock"] = self.clock
def delete(self, key : int) -> None:
if len(self.num_dict.keys()) == self.capacity and key not in self.num_dict:
min_key = -1
min_clock = float("inf")
for key, val in self.num_dict.items():
if min_clock > val["clock"]:
min_key = key
min_clock = val["clock"]
del self.num_dict[min_key]
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
delete 함수 구현부를 보면 min_clock값의 key를 찾기 위해 처음부터 끝까지 순회하는 걸 확인할 수 있다.
결과는

5%로 나올 정도로 매우 매우 매우 느린 걸 확인할 수 있다.
풀이 2
그래서 문제유형을 확인했다. 문제유형은 doouble-linked list
linked list로 O(1)을 수행하려면 넣고 빼는 작업이 바로바로 되어야 하는데 특정 노드를 list에서 찾으려면 순회가 필요하므로 로직 구성은 아래와 같이 한다.
- node는 linked list와 dictionary 둘 다 넣는다.
- 특정 node를 찾을 땐 dictionary에서 조회한다.
- linked list의 head, tail node를 구성해 앞에서든 뒤에서든 접근가능하게 한다.
- 가장 오래된, 가장 최신의 node의 경우 linked list의 순서를 조절해 넣는다.
- 가장 최신의 node의 경우, tail의 앞부분에 넣는다.
- 따라서 가장 오래된 노드의 경우 head의 다음 부분이다.
그림으로 구성해서 살펴보면
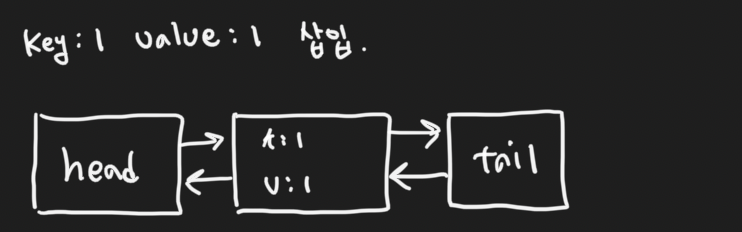
초기 상태의 경우 head와 tail 부분으로 구성된다. (capacity = 2로 설정)

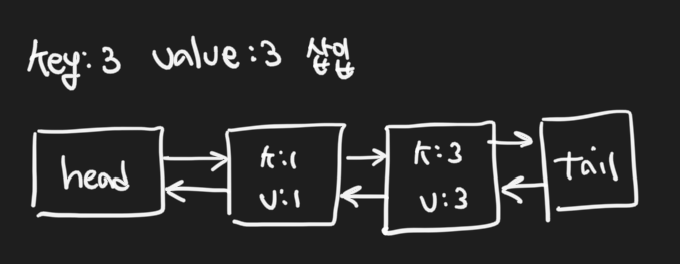
key = 1, value = 1 데이터를 삽입하면 (항상 tail 앞에 삽입)
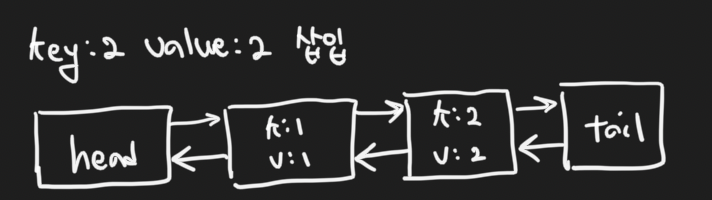
key=2, value=2 데이터를 삽입 (하면 새로운 최신데이터가 tail 앞에 삽입!)
key=1 이 조회되면 key=1인 노드는 tail 앞으로 자리를 옮겨간다.
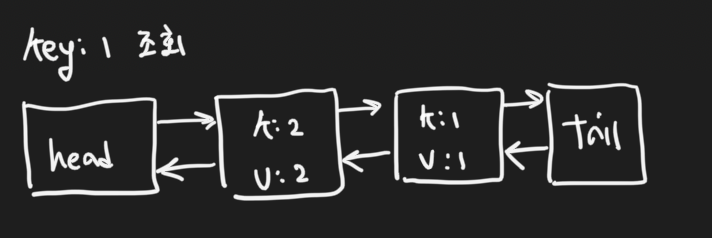
이때 key=3, value=3인 데이터가 삽입된다면
capacity가 2이기 때문에 linked list에서 가장 오래된 (head 다음의) 노드를 제거하고 새로운 데이터를
tail 앞에 넣어준다.
위 로직을 코드로 구현해 보자.
def add(self, node) -> None:
if len(self.num_dict) >= self.capacity:
remove_node = self.head.next
self.remove(remove_node)
prev = self.tail.prev
prev.next = node
node.prev = prev
node.next = self.tail
self.tail.prev = node
self.num_dict[node.key] = node
노드를 새로 추가할 땐, 기존의 공간이 꽉 찼는지 검사한 뒤, 꽉 차있다면 head다음의 데이터를 지워준다.
그런 다음 linked list에 새롭게 추가(tail 앞부분) & dictionary에 데이터를 추가해 준다.
def remove(self, node) -> None:
del self.num_dict[node.key]
prev = node.prev
next = node.next
prev.next = next
next.prev = prev
노드를 지울 땐 dictionary에서 지운뒤, 해당 노드를 linked list에서도 (head 다음 노드를) 지워준다.
전체 코드와 실행 결과를 살펴보자.
class Node:
def __init__(self, key: int, value: int):
self.key = key
self.val = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.num_dict = {}
self.capacity = capacity
self.head = Node(0, 0)
self.tail = Node(0, 0)
self.tail.prev = self.head
self.head.next = self.tail
def get(self, key: int) -> int:
if key in self.num_dict:
node = self.num_dict[key]
self.remove(node)
self.add(node)
return self.num_dict[key].val
else:
return -1
def put(self, key: int, value: int) -> None:
if key not in self.num_dict:
node = Node(key, value)
self.add(node)
self.num_dict[key] = node
else:
node = self.num_dict[key]
node.val = value
self.remove(node)
self.add(node)
def remove(self, node) -> None:
del self.num_dict[node.key]
prev = node.prev
next = node.next
prev.next = next
next.prev = prev
def add(self, node) -> None:
if len(self.num_dict) >= self.capacity:
remove_node = self.head.next
self.remove(remove_node)
prev = self.tail.prev
prev.next = node
node.prev = prev
node.next = self.tail
self.tail.prev = node
self.num_dict[node.key] = node
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)

맨 처음에 돌렸을 때 보다 속도도 빨라지고, 메모리 사용량도 확연히 줄어든 걸 확인할 수 있다.
풀이 3
python의 경우, double-linked list + dictionary(hash table) 형태인 OrderedDict라는 클래스를 제공한다.
OrderedDict 클래스는 dictionary에 삽입된 key:value 순서를 보장해 주는데,
순서가 존재하니 해당 순서를 재배치할 수 있게 함수를 제공한다.
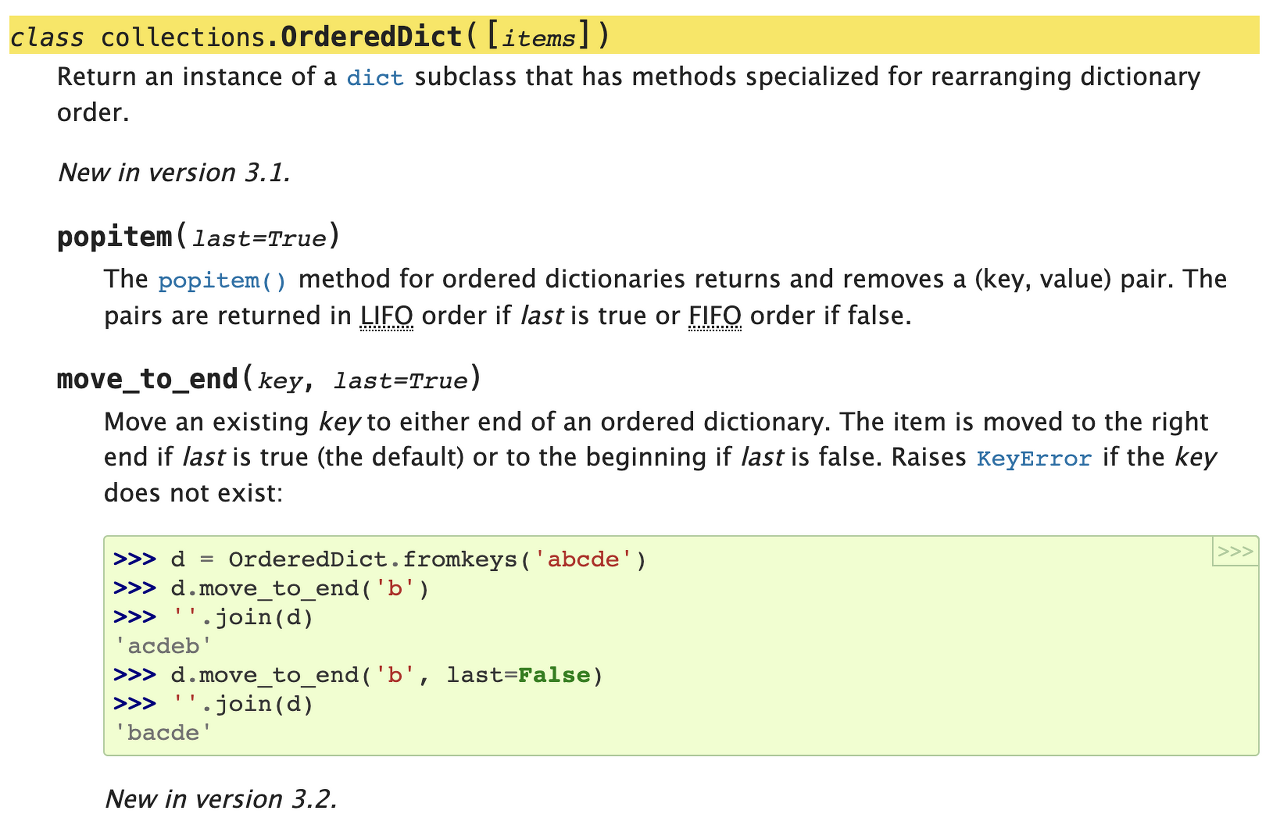
popitem의 경우, 순서중 가장 앞서 삽입된 값을 제거해 주고,
move_to_end의 경우, 특정 key 데이터의 순서를 가장 뒤로 보내주는 함수다.
위 클래스를 이용해 LRU cache 코드를 수정해 보자.
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity: int):
self.num_dict = OrderedDict()
self.capacity = capacity
def get(self, key: int) -> int:
if key in self.num_dict:
self.num_dict.move_to_end(key)
return self.num_dict[key]
else:
return -1
def put(self, key: int, value: int) -> None:
if key not in self.num_dict:
self.delete()
self.num_dict[key] = value
else:
self.num_dict[key] = value
self.num_dict.move_to_end(key)
def delete(self):
if len(self.num_dict) == self.capacity:
self.num_dict.popitem(last=False)
코드의 전체다. 엄청 줄어든 게 보인다.
get 함수 호출 시, 조회된 key에 대해 순서를 가장 뒤로 보내 최신의 데이터라고 순서를 보장해 준다.
put 함수 호출 시
- capacity를 검사해 저장공간만큼의 데이터가 존재할 때 가장 오래된 데이터를 지워준다.
- 새로운 데이터를 삽입한다
- 해당 데이터의 key값으로 순서를 가장 뒤로 보내준다.
실행결과를 보자.

실행시간이 훨씬 빨라진 걸 확인할 수 있다.
메모리의 경우, 외부 라이브러리를 import 했기에 좀 늘어난 걸까…?
그렇다면 OrderedDict는 그럼 내부 구조는 어떻게 구성되어 있을까?
놀랍게도 dictionary의 순서를 보장하는데 동일하게 doubly-linked list인걸 확인할 수 있다.
Is OrderedDict a tree?
OrderedDict is a collection that preserves order of items (in which they were inserted). I do not think this can be achieved with hashtables (which regular dict uses I think) so are balanced trees ...
stackoverflow.com
'algorithm > leetcode' 카테고리의 다른 글
| number dictionary 선언시… (0) | 2023.03.26 |
|---|---|
| Reservoir Sampling? 날 괴롭히지마 [leetcode] (0) | 2023.03.13 |
| binarySearch를 정렬된 리스트에 insert를 위해서만 사용한 나 조금 무례할지도 [leetcode] (0) | 2023.02.22 |
| circular-queue 자료구조와 문제풀이 [leetcode] (0) | 2022.09.28 |
| Trie 자료구조와 문제풀이 [leetcode] (0) | 2022.06.21 |




댓글